본 글은 논문 CUBIT: Concurrent Updatable Bitmap Indexing (VLDB'24) 를 읽고 정리한 글입니다.
별도의 명시가 없는 한, 본 글의 모든 그림은 위 논문에서 가져왔습니다.
목차
1.1. Access Path Selection
- 읽어야 할 column 이 정해진 다음에는, DBMS 는 이놈을 어떻게 읽어야 할 지 결정한다.
- “어떻게 읽어야 할 지” 라는 것에는, selectivity 가 아주 낮은 경우에는 B+ Tree 나 Trie 와 같은 tree 기반의 index 를 이용해 scan 하고 그렇지 않다면 그냥 full sequential scan 을 하는 것이 좋다는 것이 일반적인 통념이다.
1.2. Bitmap Indexes
- 여기에 추가적으로, Cardinality 가 낮은 경우에는, Bitmap Index 를 사용할 수 있다.
- 이놈은 (1) index 를 구성하고자 하는 column 에 대해 (2) 각 distinct value 마다 bitmap 을 두어서 (이것을 bitvector 라고 한다) (3) 어떤 row 가 이 distinct value 인지 표시하는 방법이다.
- 즉, 어떤 column 이 10, 20, 30 의 값만 가진다면, 10, 20, 30 에 해당하는 세개의 bitmap 을 만든 다음 어떤 row 의 column value 가 10 이면 해당하는 bitmap 의 bit 을 1 로 키는 것이다.
- 따라서 해당 column 이 개의 distinct value 를 가지고 있고, 총 row 의 개수가 이라면 이때의 bit-matrix 는 의 bit 를 가지게 되는 것이다.
- 이때문에 column 의 cardinality 가 낮아야 되는 것이다: 가 작아야 bit-matrix 의 크기도 작아지고, cardinality 는 으로 계산되니까.
- 그리고 query 를 처리할 때는 이놈을 가지고 간단한 bitwise 연산만으로 어떤 row 를 읽어야 하는지 알 수 있다 (자세한 내용은 뒤에서 알아보자).
1.3. Bitmap Index as a Secondary Index
- Bitmap index 는 Secondary index 로 사용하면 좋은데, 그 이유는
- 우선 메모리 사용량이 적다:
- (Cardinality 가 작다는 전제 하에) bit-wise 이기 때문이기도 하고,
- 뭐 tree 구조에서 필요한 pointer 와 같은 metadata 성의 데이터가 없기 때문이다.
- Clustered 되어 있다.
- 이 말은 logical order 와 physical order 와 같다는 말인데,
- 보통 secondary index 로서의 tree 는 primary index 와는 다르게 logical order 순서대로 physical 하게 저장되어 있지 않기 때문에 랜덤한 순서로 physical data 를 읽게 되고, 따라서 Pagination 에 의해 read amp 가 늘어난다.
- 하지만 bitmap index 는 logical order 와 physical order 가 같기 때문에 read amp 도 줄고 sequential memory access 이기 때문에 hardware prefetch 와 TLB miss 가 적어 더 빠르게 작동한다.
- Composition 에 더 친화적이다.
- 이것은 primary key 같은 애들이 compositive 하게 구성되어 있어서 (즉, 여러 column 으로 구성되어 있어서) foreign key 도 compositive 한데, 여기에 index 를 구성하는 경우인데,
- 기존의 B+Tree 와 같은 경우는 그냥 composite key 를 넣어야 해서 느린 반면
- Bitmap index 를 사용하면 그냥 이 column 들 각각에 bitmap index 를 구성하고 이들의 bitwise operation 으로 어떤 row 를 읽어야 할 지 결정할 수 있기 때문에 더 단순하고 빠르다.
- 이와 같은 특성때문에 기존의 B+Tree based index 보다 92% 더 적은 메모리 사용량을 보였고, scan 속도도 대략 2배정도 더 빨랐다고 한다.
- 또한, 기존에는 selectivity 가 아주 낮아야만 index scan 가 더 좋았지만, bitmap scan 으로는 selectivity 가 10% 일 때 까지도 sequential scan 보다 더 좋았다고 한다.
1.4. Challenges with Bitmap Indexes
- 하지만 이런 bitmap index 에는 치명적인 약점이 있는데, 바로 UDI (Update, Delete, Insert) 이다.
- 기존까지의 방법을 알아보면,
- 우선 update 가 발생했을 때 해당하는 bitvector 를 전부 rebuild 하거나
- Batch update 를 하거나 (즉, 일시적으로 batch update 를 위해 성능이 하락하게 됨)
- Multi-versioning + segmentation 을 하거나
- 추가적인 bitvector 를 이용해 out-of-place 방식을 취한다.
- 이 논문에서 나온 기존 연구인 UCB (Update Conscious Bitmap Index) 에서는 이 추가적인 bitvector 로 invalidate (즉, delete) 를 하고
- 저자의 이전 논문인 UpBit 에서는 update buffer 처럼 사용한다 (뒤에 자세히 나온다).
- 하지만 이러한 방법은 딱봐도 비효율적이거나 (1, 2번) 실제로 테스트해보니 비효율적이었다고 한다.
- 구체적으로는,
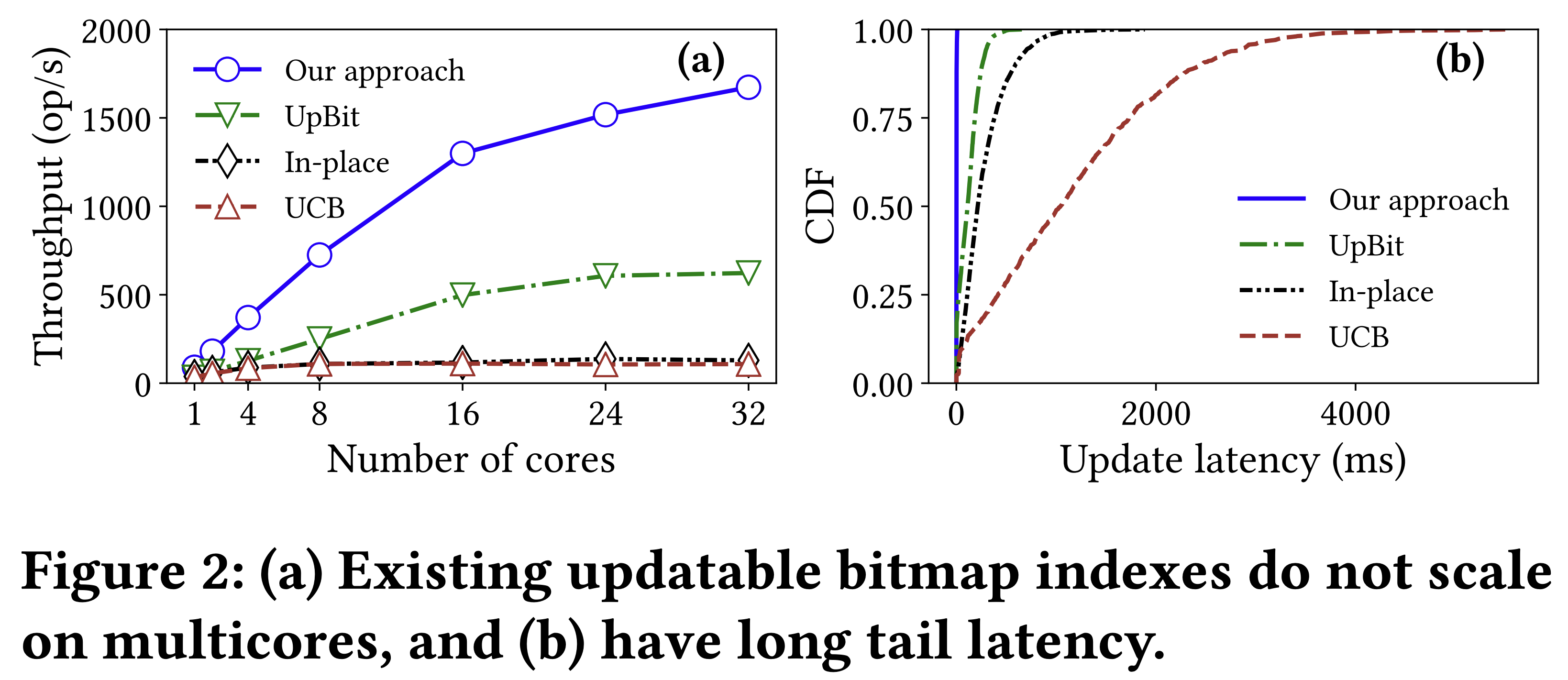
- Scalable 하지 않다는 (즉, multicore 에서는 성능이 떨어지는) 문제가 있다.
- 위 그래프를 보면 (왼쪽), 다른 solution 들은 4-core 에서부터 성능이 더 이상 오르지 않고 있고
- UpBit 의 경우에도 16-core 에서부터 성능이 꺾이고 있는 것을 볼 수 있다.
- 또한 오른쪽 그래프를 보면 16-core 에서의 tail latency 를 측정한 것인데, 아주 안좋은 것을 확인할 수 있다.
- 또한, 기존 연구들에서는 무거운 decode-flip-encode cycle 을 사용하고 있었다.
- 마지막으로 skewness 가 크다면 잘 대응하지 못한다는 것이다.
1.5. Our Approach
- CUBIT 은 상기한 문제를 해결하고 있는데, 요약하자면 latch-free out-of-place UDI 를 지원하고 decode-flip-encode 가 아닌 encoding 상태에서 바로 read / UDI 가 가능하게 만들었다.
(A) Horizontal Update Deltas
- 우선 이 논문에서는 bit-matrix 에서 update 되어 flip 될 bit 들을 row 단위로 abstract 하는 자료구조인 Horizontal Update Delta (HUD) 를 제시한다.
- 그리고 이놈에 대한 처리는 out-of-place 로 atomic 하게 하여 bitvector 전체에 대해 latch 를 잡아야 하는 문제를 해결한다.
(B) Lightweight Snapshots
- 또한 (1) Compact Delta (2) Batch-update (3) Segmentation 기법으로 Lightweight snapshot 을 구현하였으며, 따라서 read 와 UDI 가 서로 다른 snapshot 을 사용하게 하여 UDI 가 수행되는 와중에도 read 가 가능하도록 만들었다.
- 반면, tree 의 경우에는 BwTree 를 사용한다고 하더라도 atomicity 가 보장되는 범위가 더 좁기 때문에 UDI 가 read 에 영향을 미쳐 더 안좋다고 한다.
(C) Scalable Synchronization
- Bitmap index 가 contention 이 심한 이유는 bitmap index 가 cardinality 가 작은 경우에 사용되기 때문이다.
- 일반적인 경우라면 update 를 할 때 row 하나 혹은 넓게 잡아도 한 Page 에 latch 를 잡게 되지만
- Bitmap index 에서 update 를 할때 bitvector 에 latch 를 잡아버리면 위의 경우보다 더 contention 이 심해진다.
- 생각해 보면 row 나 page 에 대한 latch 는 dataset 이 큰 경우에는 전체 dataset 의 크기에 비해 아주 작은 양을 protection 하지만, 만약 column 의 distinct value 가 10 개인데 그중 하나의 bitvector 를 잡으면 (uniform 이라고 한다면) 전체의 을 protection 하는 꼴이기 때문.
- 이것은 skewness 가 크다면 더 심각해진다: 동일하게 distinct value 가 10 개이고 그중 2 개의 값이 전체 dataset 의 90% 를 차지한다면, 이들에 대한 bitvector latch 를 잡는 것은 전체의 90% 를 protect 해버리기 때문.
- 따라서 CUBIT 에서는 consolidation-aware 하게 설계하고 (뭔지는 뒤에 나온다) helping mechanism 을 사용하여 (즉, 그냥 spin-wait 을 하는게 아니고 다른 작업을 도와주는) 방식으로 이런 contention 을 줄인다.
1.6. Broader Applicability

- 따라서 이 CUBIT 의 영향을 하나의 그림으로 표현하게 되면 위와 같은 그래프로 나타낼 수 있다.
- Selectivity 가 아주 적은 경우 (few tuple) 인 경우에는 당연히 B+ Tree 가 좋고
- 10% 를 넘어서는 수준이 되면 full sequential scan 이 더 좋으며
- 그 중간 구간에서는 bitmap index 가 좋다.
- 그리고 기존까지는 update rate 가 적은 경우에만 bitmap index 를 사용할 수 있었다면,
- CUBIT 은 update rate 가 높은 경우에서까지 지 bitmap index 를 사용할 수 있도록 확장시킨 것이다.
- 이러한 장점때문에 CUBIT 은 batch-update 를 하는 ETL 기반의 OLAP DBMS 혹은 HTAP 시스템에서 활용될 수 있고,
- Index 로서 활용하는 것 뿐 아니라 JOIN 이나 Aggregation operator 에서 필요한 정보를 줄 수도 있다고 한다.
1.7. Contributions
- 기존의 updatable bitmap index 를 multicore 에서 돌려 이들의 bottleneck 을 찾았고, 이것을 (1) Horizontal Update Delta (2) Lightweight snapshotting (3) latch-free design 으로 해결한 in-memory bitmap index 인 CUBIT 을 제시한다.
- 구현된 CUBIT 을 다른 baseline 들과 비교하여 multicore 환경에서 테스트하였고, 최대 16배의 throughput, 그리고 read latency 는 최대 13배, UDI latency 는 최대 220배 줄였다.
- 또한 이 CUBIT 을 DuckDB 와 DBx1000 에 구현하였고, TPC-H 와 CH-benCHmark 로 실험하였다.
- 이러한 점을 감안했을 때, CUBIT 으로써 HTAP 환경에서도 bitmap index 를 사용할 수 있도록 그 활용성을 확장했다.