참고한 것들
Database Management System, DBMS
- Database 를 관리하는 소프트웨어를 일컫는다.
- 즉, client 에게는 데이터를 관리하는 API 를 제공하고, 그리고 그에 따라 데이터를 관리하는 놈이다.
- Client 와 data 사이에 있는 layer 인 셈.
DBMS 의 필요성: Raw CSV-DB approach
- 그냥 CSV (Comma-Separated Value) 형태로 데이터를 저장하고 사용한다면 어떤 일이 벌어질가?

- 그리고 이런 방식으로 원하는 정보를 추출한다면?
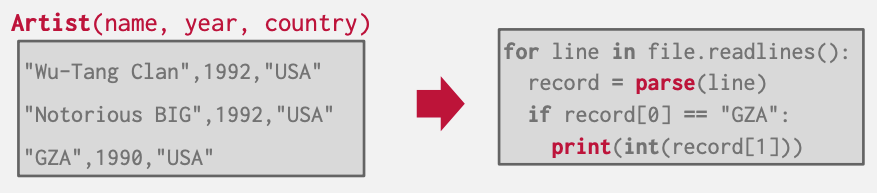
- 이때 고려할 점들은 다음과 같다:
- 우선 데이터의 integrity 와 관련해서는:
- 데이터 중복을 막아야 한다.
- 즉,
Artist에"GZA"와"gza"가 모두 들어가거나,"GZA"가 두개 들어가는 경우 등.
- 즉,
- 자료형에 대한 규제를 해야 한다
- 정수값을 가져야 하는
year항목에 문자열이나 이메일이 들어가는 등의 상황을 막아야 한다. - 아니면 뭐 값이 가질 수 있는 범위나 그런 메타데이터 정보
- 정수값을 가져야 하는
- 실생활에서의 한 Album 에 여러 Artist 가 참여한 경우를 반영할 수 있도록 해야 한다.
- 한 Artist 를 지우면 해당 Artist 의 Album 를 선형탐색하며 지워야 한다.
- 데이터 중복을 막아야 한다.
- 이 CSV-DB 를 사용하는 application 을 구현하는 입장에서:
- 탐색이 너무 오래걸린다; 을 감당해야 한다는 것..
- Application process 가 다른 머신에서 작동한다면?
- 여러 process/thread 가 하나의 DB 에 접근한다면 이때의 concurrency 는 어떻게 처리할까?
- CSV-DB 의 가용성 측면에서는:
- 만약 application 이 이 DB 를 사용하다가 꺼져버린다면 어떻게 이것을 복구할 수 있을까?
- 이 DB 를 HA 를 위해서 replication 을 하고자 한다면 어떻게 해야 할 까?
- 우선 데이터의 integrity 와 관련해서는:
- 이러한 문제들을 모든 application 에서 처리하는 것보다는, 처리해주는 “누군가” 가 있으면 더욱 좋을 것이다. 그놈이 DBMS 인 것.
Classification
- DBMS 는 경장히 general 한 용어이고, 여기에는 많은 분류가 가능하다.
- 데이터 모델 에 따라서는 다음 정도로 분류해 볼 수 있다: