충남대학교 컴퓨터공학과 류재철 교수님의 "운영체제 및 실습" 강의를 필기한 내용입니다.
다소 잘못된 내용과 구어적 표현 이 포함되어 있을 수 있습니다.
가상메모리
- 봐봐라
- 실제로는 프로그램의 전부가 메모리에 올라가는 것이 아닌 프로그램의 페이지 일부만 메모리에 올라가게 된다
- 그리고 실제로는 페이지들이 하드에나 메모리에나 연속된 공간에 있지 않고 다 흩어져 있다
- 하지만 우리가 생각할때는 이 페이지들이 전부 메모리에 연속적으로 적재되어있다고 생각하고 프로그램을 짜게 된다 - 이렇게 사용자입장에서 생각하기 편하게 하려고 착각을 유도하는 기법을 가상 메모리(Virtual Memory) 라고 한다
- 이렇게 가상 메모리 기법을 적용한 paging을 일반 paging과 구분해 Virtual Memory Paging이라고도 부르더라
- 마찬가지로 가상 메모리 기법을 적용한 segmentation을 Virtual Memory Segmentation이라고 한다
- 이렇게 함으로써 우선 메모리 사이즈보다 더 용량이 큰 프로그램도 메모리에 적재시킬 수 있고, 프로그램 전부가 올라가지 않기 때문에 더 많은 프로그램을 적재할 수 있어 Multiprogramming에서도 이점이 있다(Multiprogramming level을 높일 수 있다)
- 그리고 이것은 프로그램 개발자의 관점에서도 프로그램 크기에 따라 다르게 프로그래밍 할 필요가 없다는 이점이기도 하다
- 이때 원하는 페이지가 메모리에 적재되어있지 않고 하드에 들어있을때 Page fault가 일어나게 된다 - 이렇게 page fault가 일어나면 block을 먹고 IO operation이 일어나며 가져오고난 뒤에는 인터럽트를 걸고 다시 ready상태로 바뀐 다음에 dispatch되면 실행되는 과정을 거치는 것
- 가상메모리가 잘 구동되기 위해서는 물리적으로 메모리 공간을 나눠 page가 들어올 frame들을 구성하는 하드웨어적인 역할 과 page replacement같은 기능을 수행할 소프트웨어적(운영체제적)인 역할 이 중요하다
Page 사이즈 정하기
- Page 사이즈가 작으면 만약에 page fault가 일어났을때 한번에 가져오는 양이 적기 때문에 page fault가 자주 일어나게 된다
- 또한 page table의 사이즈가 커져 PCB가 커지기 때문에 많은양의 메모리를 먹게 된다
- 하지만 반대로 page 사이즈가 너무 크면 작은 프로그램의 경우에는 page하나에 담기고 남은 부분이 internal fragmentation이 되기 때문에 메모리의 낭비가 생기게 된다
- 이렇듯 운영체제를 설계할때는 항상 대조되는 선택지의 장단점이 존재하기 때문에(Trade-off라고 한다) 이것을 잘 조화시켜서 최선의 결과를 내는 Optimal Design이 중요하다
- 요즘의 경우에는 메인메모리의 값이 그렇게 비싸지 않기 때문에 fragmentation이 그렇게 큰 문제가 안돼 page의 사이즈를 크게 하는것이 추세란다
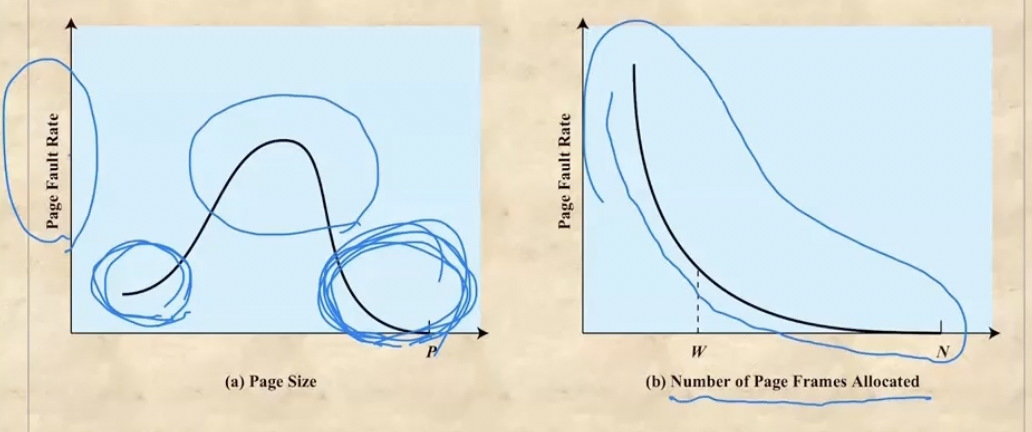
- 첫번째 그래프에서 왜 사이즈가 작을때 page fault가 작아지는지는 모르겠음 - 어중간할때는 왜 큰지도 모르겠음
- 어쨋든 사이즈가 커지면 한번에 많이 갖고오므로 page fault가 잘 안일어난다는게 중헌것이고
- 두번째 그래프는 프로세스 하나에 대해 frame이 몇개가 할당되는지에 대한 그래프다. 높을수록 프로세스 하나에 많은 frame을 할당받으므로 메모리에 올라갈 수 있는 프로세스의 갯수는 적어지고 대신 보다시피 page fault rate는 적어진다

- 근데 할당되는 프레임의 갯수가 많아지면 rate가 줄어야 정상인데 replacement algorithm 이 잘못되면 저렇게 rate가 치솟는 현상이 생기고 이것을 Belady’s anomaly라고 한다
Page Replacement
- 이전에 프로세스가 메모리에 들어와야 되는데 메모리에 자리가 없으면 한놈이 자리를 비켜주고 하드로 내려가는거를 swapping이라고 했는데
- Paging기법에서도 동일하게 메모리에 자리가 없으면 어느 한 놈이 자리를 비켜주는 동작을 하게 되고 이것을 Page Replacement라고 한다
- 근데 이때 아무 page나 내려보내게 되면 프로그램이 비효율적으로 동작할 수도 있다
- 즉, page 교체 알고리즘에 따라서 동작의 효율성도 달라질 수 있다는 소리임
- 뭐 예를 들면 우선순위가 비교적 높은 놈의 page를 내려보내면 얘를 조만간 다시 갖고 올라와야되기 때문에 page fault가 자주 일어나 IO request도 자주 일어나게 되는 것
- 그리고 page는 어차피 원본의 page가 하드디스크에 저장되어있기 때문에 메모리에 적재되어있던 page와 하드디스크에 있던 원본의 page가 차이가 없으면 하드로 내려보낼 때 굳이 새로 write하지 않고 하드에서 올라오는 page를 그 자리에 overwite하게 된다
- 하지만 메모리에 올라와있던 page에 변경이 생기게 되면 그제서야 하드에 write하는 작업을 하게 된다
- 그리고 이제 안그래도 IO가 일어나서 기다렸는데 자리가 없어서 replacement까지 일어나면 OS입장에서는 굉장히 기다리는 시간이 아까우므로 OS는 항상 일정한 수만큼 blank(비어있는) frame을 만들어놓는다 - 그래서 IO가 끝나면 바로바로 올릴 수 있게
위에꺼를 반영한 paging / segmentation

- 여기서 페이지 테이블의 한 행의 구조를 나타낸 것이 아래 그림인데 보면 frame number만 있는게 아니고 앞에 Control Bit가 붙는다
- 얘는 데통에서 헤더마냥 frame / page 의 여러가지 정보를 담는 부분이다
- 일단 P는 이 page가 현재 메모리에 적재되어있냐를 나타내는 비트(Present)이다.
- 즉, 이게 enable되어 있으면 frame number부분에 유효한 number가 들어가 있을 것이고
- disable되어 있으면 메모리에 적재되어있지 않다는 뜻으로 유효하지 않은 number가 들어있게 된다
- 그리고 M은 이 page가 변경되었냐를 나타내는 비트(Modified)이다
- 위에서 설명한것처럼 page replacement를 할 때 변경되지 않았으면 굳이 하드에 write를 하지 않아도 되기 때문
- segmentation의 경우에도 앞에서 배운거랑 마찬가지되 P, M이 붙게 된다
Paging의 address translation 방법 복습
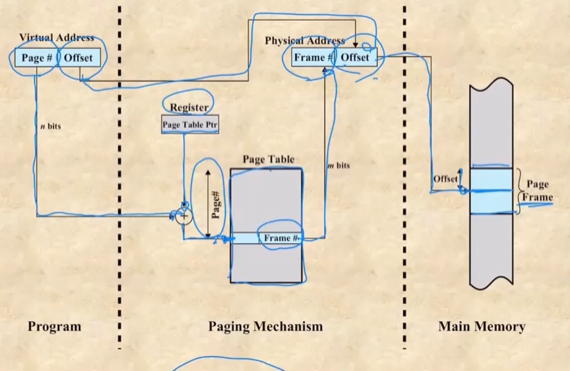
- 가상 주소에서 offset은 그대로 가고 page# 을 이용해 frame# 를 찾는거
- 레지스터에 저장된 page table의 시작점, 즉. page table ptr을 이용해 page table로 이동하고, page# 를 인덱스로 하여 frame# 을 얻어내 physical address를 얻어내는 것
Thrashing
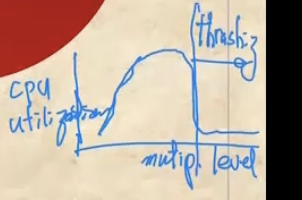
- 봐봐라
- 메모리에 많은 프로세스가 올라가게 되면, 즉, multiprogramming level이 올라가게 되면 당연히 cpu utilization도 늘어난다
- 근데 multiprogramming level이 늘어난다고 무조건적으로 좋은것은 또 아니다 이말이야
- 왜냐면 multiprogramming level이 늘어나면 하나의 프로세스에게 할당되는 공간이 줄어들고 그러면 page fault가 더 자주 일어나게 되기 때문이다
- 그래서 저 위의 그래프에서 보이듯이 일정수준까지는 multiprogramming level이 늘어갈수록 cpu utilization도 늘어나게 된다.
- 하지만 그 수준을 넘어서게 되면 위에서 설명한것처럼 page fault가 자주 일어나 cpu utilization이 급격하게 하락하게 된다
- 이 지점을 Thrashing이라고 하는 것. 즉, multiprogramming level이 과도하게 많아지면 page fault가 너무 자주 일어나 cpu utilization이 급락하는 것을 의미한다
- 따라서 운영체제 입장에서는 Thrashing은 반드시 막아야 되는 현상이다
- 따라서 multiprogramming level이 너무 낮으면 프로세스 하나가 블락을 먹었을때 대체제의 선택폭이 좁아져 cpu utilization이 안좋고 또 너무 높으면 thrashing이 일어나기 때문에 안좋아져서 적절한 level을 잡는 것이 중요 하다
Locality - 지역성
- 만약에 프로그램에 while문이 하나 있다고 하고 이부분이 세개의 page로 나뉘어졌다고 해보자
- 근데 만약 메모리에 공간이 없어서 두개의 frame밖에 할당하지 못한다면 루프가 돌때마다 page fault가 일어나므로 아주 효율성이 떨어질 것이다
- 따라서 다음과 같은 경우에는 해당 프로세스에게 3개 이상의 frame을 할당하는 것이 효율성을 높이게 된다
- 이렇듯 프로세스를 이루는 page들 중에서도 집중적으로 실행되는 page들을 중간에 끊지 않고 전부 메모리에 올려 page fault를 줄이는 것을 지역성(Locality) 이라고 한다
Combined segmentation & paging

- 이부분은 별로 설명 안함 - 가상메모리에 page# 와 seg# 둘 다 있어서 page table과 segment table을 둘 다 이용한댄다
Multi-Level Hierarchical Page Table
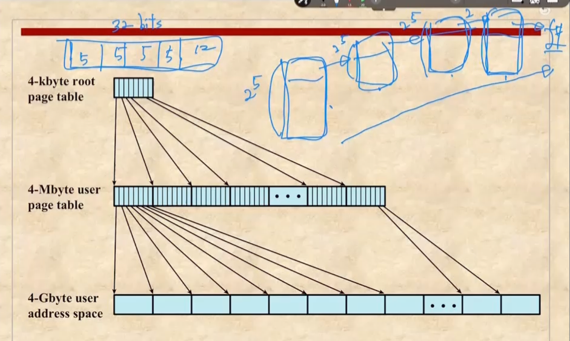
- page table을 다계층 구조로 만들어 page table의 사이즈를 줄이는 기법이다
- 봐봐라
- 만약에 page# 에 20비트가 할당되어있고 offset이 12비트인 32비트 체제라면 page table의 길이는 2의 20승이다
- 하지만 프로그램의 크기가 작아서 page가 몇개 되지 않는다면 2의 20승 중에 일부만 사용하고 나머지는 버리게 되는 셈이다
- 근데 이것을 두개의 계층으로 나누면 첫 10비트는 첫번째 계층 table에서의 index를 나타내고 나머지 10비트는 두번째 계층 table에서의 index를 나타내는데
- 만약에 프로그램을 구성하는 page의 갯수가 2의 10제곱보다 작으면 하나의 2^10 사이즈 테이블로 모든 page# 에 대응되는 frame# 을 저장할 수 있자네
- 이때 이 2^10 사이즈 테이블이 2계층 테이블인거고 이 2계층 테이블들로 접근할 수 있도록 얘네들의 주소를 담고 있는 테이블이 1계층 테이블인 것이다
- 따라서 page의 사이즈가 2^10보다 작으면 1계층 테이블에는 하나의 원소만 존재하고 2계층 table하나만 있어도 모든 page에 대응되는 frame을 저장할 수 있으므로 메모리를 2^11 만 차지하게 되는 것 - 계층구조를 도입하기 전인 2^20에 비해 엄청난 양의 공간을 절약할 수 있다
- 이런식으로 가상주소의 page# 구역을 여러개로 쪼개 page table하나로 모든 page에 대응하는 것이 아닌 page table을 계층적으로 구조화해 동적으로 page table이 생성되며 메모리를 절약하는 방식 이 Multi-Level Hierarchical Page Table인 것이다
- 다만 이 방식에 장점만 있는 것은 아니다 - 다계층이 될 수록 address translation은 복잡해지기 때문에 수행시간이 오래 걸리는 것 = 공간과 시간이 반비례하는 현상이 여기서도 나타나게 되는 것이다
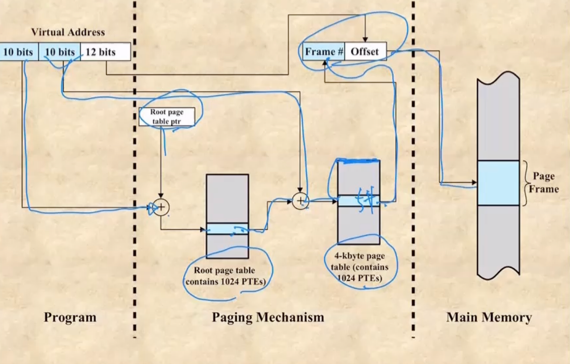
- 따라서 보면
- 첫 10비트와 page table ptr를 통해 알아낸 1계층 테이블로 이 가상주소의 frame# 을 담고 있는 2계층 테이블의 주소를 알아낸다
- 그리고 2계층 테이블로 가서 두번째 10비트를 이용해 frame# 을 알아내게 되는 것
Inverted Page Table
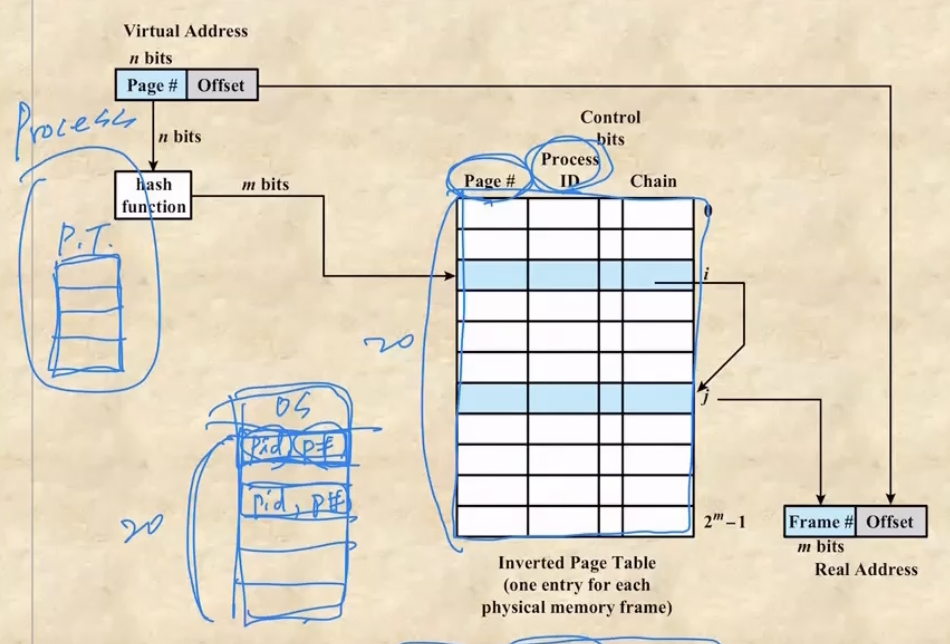
- 봐봐라
- 일단 Inverted Page Table의 개념은 프로세스들마다 존재하는 page table을 하나로 합쳐 OS에 하나만 존재하는 테이블로 만드는 것이다
- 이렇게 바꾸는 과정은 약간 데베식의 설명을 곁들이면 하나의 frame# 을 특정하기 위해서는 page# 와 pid를 기본키로 하면 특정할 수 있다
- 근데 프로세스마다 존재하는 page table은 이미 pid가 PCB에 저장되어있기 때문에 page# 만으로 하나의 frame# 을 특정할 수 있었던 것 인데
- 이것을 이제 하나의 테이블로 합치면 pid는 알 수가 없기 때문에 pid 어트리뷰트를 하나 추가하고 거기에 대응되는 frame# 을 저장하는 것 - 저기 그림에서 Chain이라고 표시된 부분이 frame# 이 저장되는 부분이다
- 근데 하나의 메모리 공간을 여러 프로세스가 공유하는 경우도 생긴다 - 뭐 공유 메모리라던가, 하나의 프로그램을 여러번 실행시켜 read-only인 코드는 여러개의 프로세스가 공유하는 등
- 이것을 지원해주기 위해 chain값으로 다른 프로세스의 페이지가 담긴 frame# 을 넣어서 참조하게 할 수 있다
- 따라서 page# 을 가져와서 테이블에서 자신과 page# 와 pid가 같은 인스턴스를 찾아 chain 어트리뷰트의 값인 frame# 을 받아 address translation 을 하는 것
- 이때에는 찾는 과정을 빠르게 하기 위해 hash function을 이용한다 - 파이썬 딕셔너리할때 그 해시임
Lookaside Buffer
- 얘는 저장장치의 한 종류인데
- 보통 하나의 값을 배열에서 찾거나 할때는 처음부터 serial하게 쭉쭉 찾아나가자네?(O(n))
- 근데 이걸 사용하면 배열의 모든 원소를 한번에 비교해 원하는 값을 찾는 것 같은 기능을 제공해준다(O(1))
- 저장장치의 한 종류이므로 하드웨어이고 이런 강력한 기능을 제공하는 대신 좀 비싸다
- Virtual -> physical memory ddress translation을 담당하는 lookaside buffer를 Traslation Lookaside Buffer(TLB) 라 하고 얘는 레지스터의 한 종류이다
얘를 이용해 address translation을 하는 방법
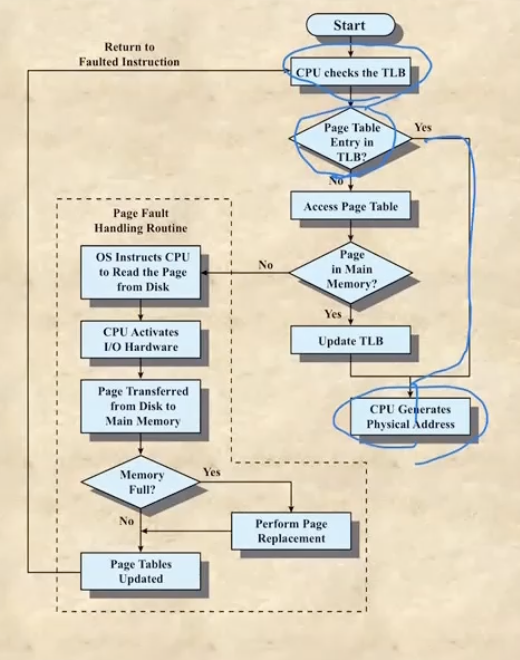
- Page table의 일부분을 저 TLB로 올린다
- 이제 가상주소 하나를 translation할 때 page# 을 저기 TLB에 먼저 넣어본다
- 만약에 hit(찾음) 이면 바로 frame# 가 나오게 되고 miss(못찾음) 이면 이제 그제서야 page table로 가서 serial하게 찾게 된다 - page table의 일부분만 TLB에 올라갈 수 있으므로 miss될 수 있다
- 찾으면 Locality를 활용하기 위해 TLB에 이 page를 넣어놓는다 - 또 사용되면 빠르게 hit시키기 위해 → 그리고 translation을 해 frame# 을 얻어내는 것
- 하지만 page table에서 봤더니 얘가 메모리에 없을 수도 있다 - 그러면 page fault handling routine이 실행되어 이놈을 갖고오고 처음부터 다시 하게 되는 것
- 이 방법은 운이 없어서 miss가 뜨면 TLB에 접근하는 시간만큼 손해이긴 하다
- 하지만 위에서 말한 Locality를 이용하면 hit의 비율을 90퍼센트 이상으로 끌어올릴 수 있고 이러면 serial하게 비교하는 경우가 거의 없기 때문에 아주 빠르게 address translation이 가능하다
Cache
- 캐시도 TLB와 비슷하게 one-time search를 지원해주는 저장장치이다
- physical address를 구하고 나서 원래는 이 주소에 해당하는 메모리 공간으로 가 instruction을 실행하는데
- 메모리에 가기 전에 먼저 cache에 가서 이 주소에 대한 instruction이 이미 존재하는지를 찾는다
- 그래서 만약에 hit라면 바로 cpu로 올려 실행하게 되는 것 이고
- 아니면 그제서야 메인메모리의 해당 주소로 가게 되는 것