이화여자대학교 컴퓨터공학과 반효경 교수님의 "운영체제 (KOCW)" 강의를 필기한 내용입니다.
다소 잘못된 내용과 구어적 표현 이 포함되어 있을 수 있습니다.
System Structure
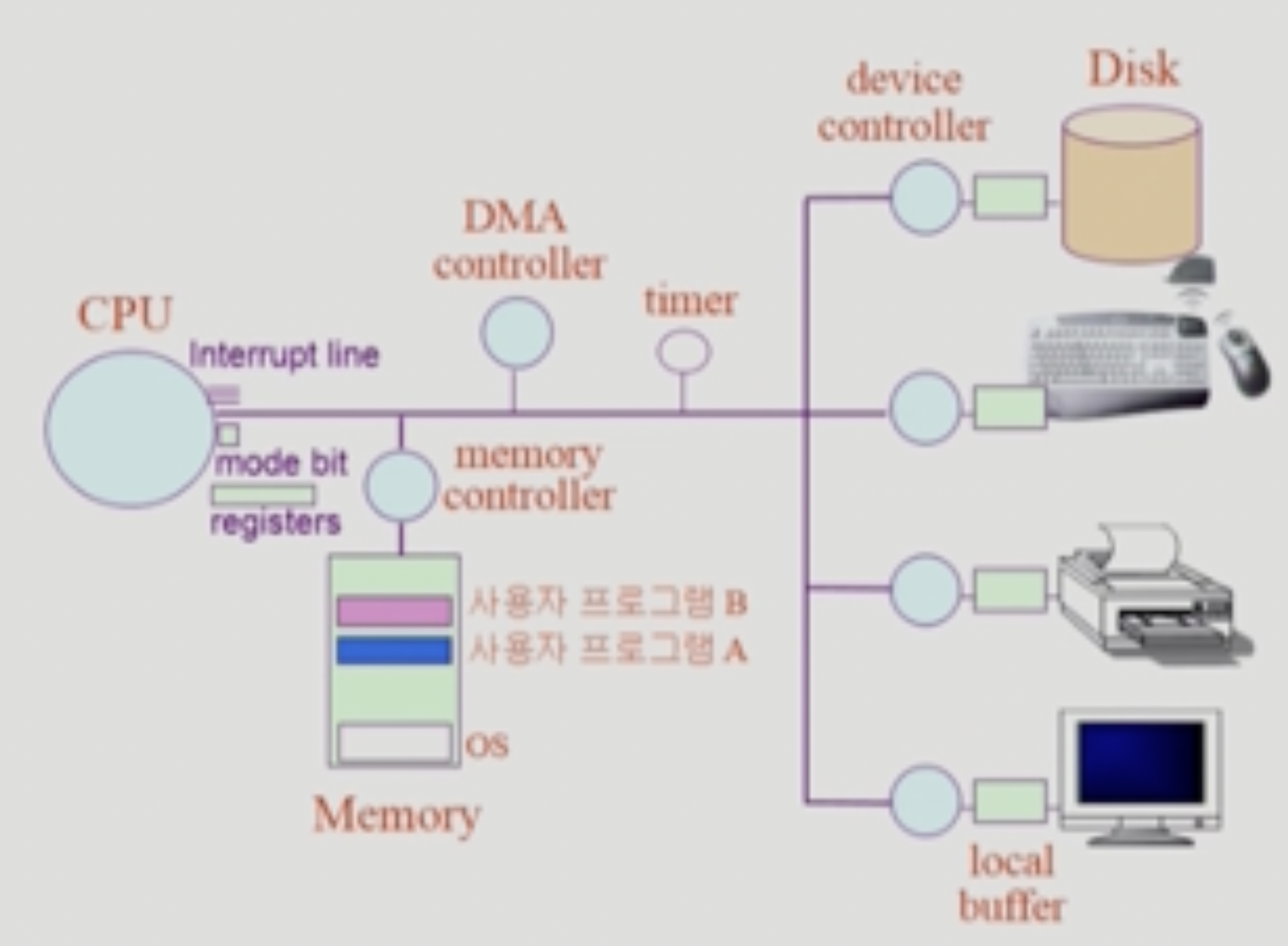
- CPU + Memory = Computer
- 나머지 디스크 키보드 등은 IO Device 라 부른다.
- Memory 는 CPU 의 작업공간이라 할 수 있음 → Instruction들을 하나씩 메모리에서 읽어다 실행시키게 됨 → PC가 메모리의 주소를 가리키기 때문
- CPU의 유일한 업무는 PC가 가리키는 Instruction을 가져와서 실행시키는 것 밖에는 없다.
- Device controller: 각 device들을 관리하는 작은 CPU같은놈
- Device controller 는 제어정보를 위한 Control register와 Status register 도 추가적으로 가진다
- 또한 정보를 임시적으로 저장하기 위한 Buffer 도 존재함 → Local buffer
- 이 Local buffer 에는 CPU(근데 대부분 DMA Controller) 가 접근해서 IO처리가 끝난 데이터들을 가져온다.
- 근데 이제 Device controller 가 실행해야 되는 Instruction은 어떤 형태로 제공되느냐
- 니가 많이 들어봤던 펌웨어 가 이러한 역할을 해준다 → 펌웨어가 약간 디바이스의 OS라 할 수 있는거지
- Device driver: 컨트롤러가 하드웨어였다면 얘는 소프트웨어다 → 각 장치별 처리 루틴을 담은 OS 의 코드 일부분
- 펌웨어는 실제로 디바이스 컨트롤러가 실행하는 Instruction이고 Device Driver 는 CPU가 실행하는 디바이스를 관리하기 위한 Instruction 이라는 차이가 있더라
- Mode bit: 현재 실행중인 Instruction이 User mode 인지 Kernel mode 인지를 저장하는 플래그
- 일반 사용자 프로세스가 시스템적으로 중요한 작업을 직접 할 수 없도록 하드웨어적으로 막아놓음
0: 모니터(커널, 시스템) 모드 → 보안을 해칠 수 있는 중요한 명령어(Previleged instruction)들을 수행할 때1: 사용자 모드 → 일반 사용자 프로세스가 사용할 수 있는 안전한 명령어- OS로 전환되기 전에는 해당 플래그가 0으로 바뀌고 다시 사용자 모드로 가기 전에는 1로 바뀐다.
- Mode bit 이 1일때는 특정 프로세스의 메모리 공간밖에 접근할 수 없고 0일때는 모든 메모리 공간에 접근할 수 있다더라
- Interrupt line: IO 등의 인터럽트들이 들어오는 통로
- CPU는 메모리랑만 작업하고 그 외의 것들에는 관여하지 않는다
- 따라서 IO 등의 작업이 필요할 경우에는 해당 작업을 Device controller 등에게 위임한 뒤 다시 메모리에 있는 Instruction들을 실행한다.
- 만일 Device controller 가 작업을 마치게 되면 그때 인터럽트를 걸게 되는데
- CPU는 Instruction 하나를 실행한 이후 매번 Instuction line 을 체크해서 들어온 인터럽트가 있는지 확인하고
- 인터럽트가 있으면 해당 인터럽트를 먼저 처리하게 된다
- 얘는 소프트웨어적으로 큐형식으로 작동한다기보다는 하드웨어적 버스로 구성되어 전기신호를 보냄으로써 인터럽트가 걸리게 하는거 같다 → 근데 확실하지는 않음
- Timer: 프로그램의 CPU time을 재는 타이머
- 프로그램이 IO 등을 만나면 이거때문에 더이상 해당 프로세스에서는 작업하지 못하므로 제어권이 딴놈에게 넘어가지만
- 만일 IO가 안일어나면 이놈만 CPU를 잡아먹고있는 Monopolize 가 발생한다
- 따라서 Context switching 이 일어나기 전에 Timer를 설정해놓고 실행하다가 타이머가 종료되면 Timer 인터럽트를 걸어 딴놈으로 옮겨갈 수 있도록 함
- DMA(Direct Memory Access): IO 디바이스에 의한 인터럽트는 생각보다 빈번하게 발생하기 때문에 매번 CPU에 인터럽트를 걸면 경장히 비효율적이다.
- 따라서 저 DMA라는 놈이 중간다리 역할을 하게 되는데
- 이름에서부터 알 수 있듯이 얘도 CPU와 마찬가지로 메모리에 접근할 수 있다.
- 따라서 인터럽트가 발생할때마다 CPU대신 이놈이 메모리에 적재를 해주고
- 몇 바이트 수준이 아닌 블럭 단위의 좀 많이 데이터가 모이면 그때 한번에 인터럽트를 걸어서 CPU가 알 수 있도록 해준다.
- 근데 메모리에 CPU랑 DMA가 같이 접근하게 되면 동기화 문제가 발생하기 때문에
- Memory controller 가 마치 세마포마냥 접근을 중재해주게 되는 것이다.
Trap, Syscall, Exception
- 프로세스는 IO 등의 커널 함수가 필요하면 직접 실행하거나 OS가 먼저 해주는게 아니라 프로세스가 OS에 요청하는 식으로 작동한다.
- 왜냐면 사용자 프로그램이 실행되고 있을때는 Mode bit 이 1이기 때문에 권한이 없어 메모리의 커널 영역으로 점프하지 못하기 때문
- 따라서 일반적인 함수나 분기, 반복과는 다른 방식으로 작동한다.
- 사용자 프로세스는 커널 함수를 요청하기 위해 일종의 인터럽트를 걸어 해당 함수가 실행될 수 있도록 하는데 → 이런 인터럽트를 거는 과정 덕분에 Mode bit 이 0으로 바뀔 수 있고 따라서 커널 영역의 Previleged Instruction들을 실행할 수 있더라.
- 이렇게 사용자 프로세스가 커널 함수를 호출하는 것을 Syscall(System call) 이라고 한다.
- 사용자 프로세스가 인터럽트 비스무리한걸 거는 경우가 한가지 더 있는데 바로 어떤 값을 0으로 나누려 하는 경우 등의 Exception 이 발생했을 때이다.
- Syscall하고 Exception을 합쳐서 사용자 프로세스가 거는 인터럽트 비스무리한걸 Trap 혹은 Software Interrupt 이라고 하더라
- Syscall 또한 어찌보면 사용자가 요청하는 커널 함수이기때문에 올바른 요청이냐에 대한 검증이 선행된다.
- 그니까 대략 이런식으로 움직임 → IO 의 경우 예시임
- IO가 필요할 때 프로세스(A)는 해당 기능을 호출한다. (Syscall - Software Interrupt)
- OS가 CPU를 차지하며 해당 Device controller 에게 일을 시킨다.
- 다른 프로세스(B)로 CPU가 전환
- IO 작업이 끝나면 해당 Device controller 에 의해 IO 인터럽트 발생 (Interrupt - Hardware Interrupt)
- 그러면 DMA가 Device 에 있던 Buffer에서 데이터를 가져다가 메모리에 적재하고 즉당한 시점에 CPU에 인터럽트를 건다
- CPU 가 다시 OS로 전환되며 해당 인터럽트를 처리
- IO 인터럽트때문에 멈춰있던 프로세스(B)로 CPU가 넘어오며 진행 → 무조건은 아니고 일반적으로는 거렇다더라
- IO를 요청한 프로세스(A)로 CPU가 넘어오며 다시 작업 진행
Interrupt Handling
- Interrupt Service Routine: 얘는 특정 인터럽트가 걸렸을때 실행되는 Instruction 모음이다. = 해당 인터럽트를 처리하는 커널 함수
- Interrupt Vector Table: 얘는 위의 ISR들에 대해 인터럽트 번호-ISR 주소(위치) 를 매핑시켜놓은 테이블이다
- 이것 덕분에 특정 인터럽트가 발생했을 때 그걸 처리하는 ISR이 어느 위치에 있는 지 알 수 있게 되고 해당 ISR 이 실행되게 되는 거다.
Synchronous, Asynchronous IO
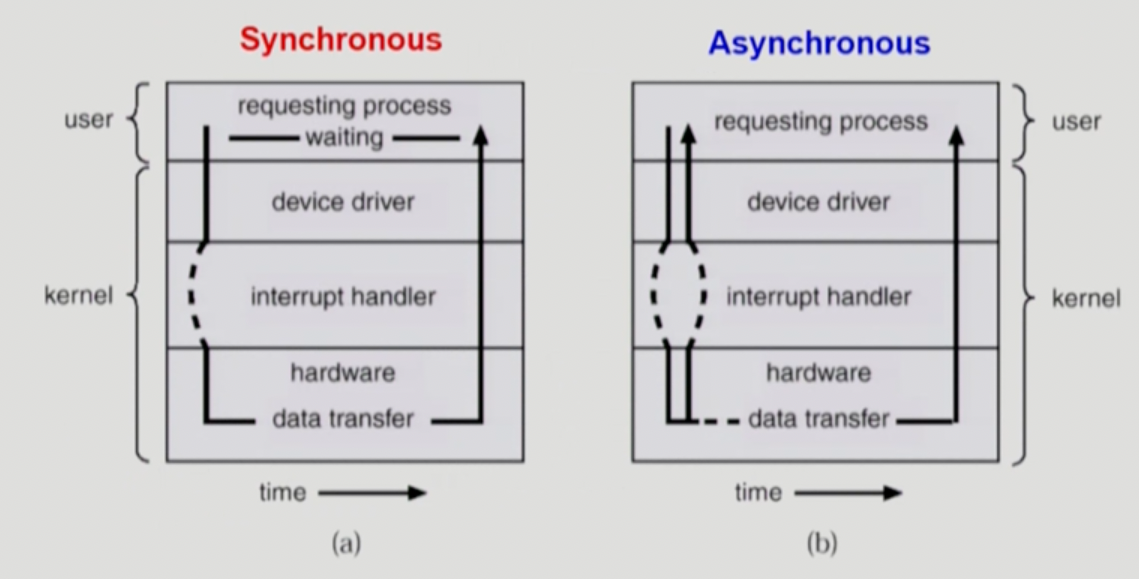
- 얘는 뭐가 좋고 뭐가 나쁘고가 아니고 걍 구현방식의 차이인데
- 먼저 Synchronous IO 는 IO요청을 한 다음에 해당 IO가 끝날때까지 요청한 프로세스는 기다리다가 IO 인터럽트가 걸리면 그제서야 다시 프로세스가 재개되는 방식이고
- Asynchronous IO 는 끝날때까지 기다리지 않고 요청하는 작업을 끝내자마자 요청한 프로세스로 돌아갔다가 나중에 IO 인터럽트가 걸리면 데이터를 가져와서 계속 일하는 방식이다.
- 일반적으로는 Synchronous 의 경우에는 읽기 작업에 많이 사용된다 → (보통은) 데이터를 읽어들인 다음에 그 데이터를 가지고 계속 작업하는 것이 순리이므로
- 그리고 Asynchronous 는 쓰기 작업에 많이 사용된다 → (보통은) 데이터를 화면이나 디스크에 쓴 다음에는 프로세스에서 해당 데이터를 쓸 일이 많지 않기 때문
- 물론 뭐 정해진건 아니다 → 읽기 요청도 Asynchronous 로 구현하거나 쓰기 요청도 Synchronous 로 할 수도 있다
Implementation of Synchronous IO
- Synchronous IO 는 구현방법이 2가지 인데 보통 후자의 방법으로 많이 한다.
- 먼저 첫번째는 IO가 끝날때까지 Busy waiting을 하는 방법이다 → 즉, IO가 끝날때까지 CPU가 해당 프로세스와 함께 대기하는 방법
- 하지만 당연하게도 이 방법은 비효율적이다
- 비싼 자원인 CPU가 놀고 있다는 점에서도 그렇고
- IO가 하나 걸리면 딴거를 못하니까 IO 요청도 한번에 하나밖에 못하기 때문
- 그래서 두번째 방법은 해당 프로세스로 CPU time 을 주지 않는 방법이다
- 이렇게 하면 해당 프로세스가 어차피 실행되지 않기 때문에 자동으로 대기상태가 되는 효과가 있고
- CPU가 다른 프로세스로 옮겨가기 때문에 CPU time을 낭비하지도 않으며
- 다른 IO syscall이 들어와도 일 시켜놓고 또 다른 프로세스로 넘어가면 되기 때문에 IO 요청도 여러개 받을 수 있다.
IO Instruction Type
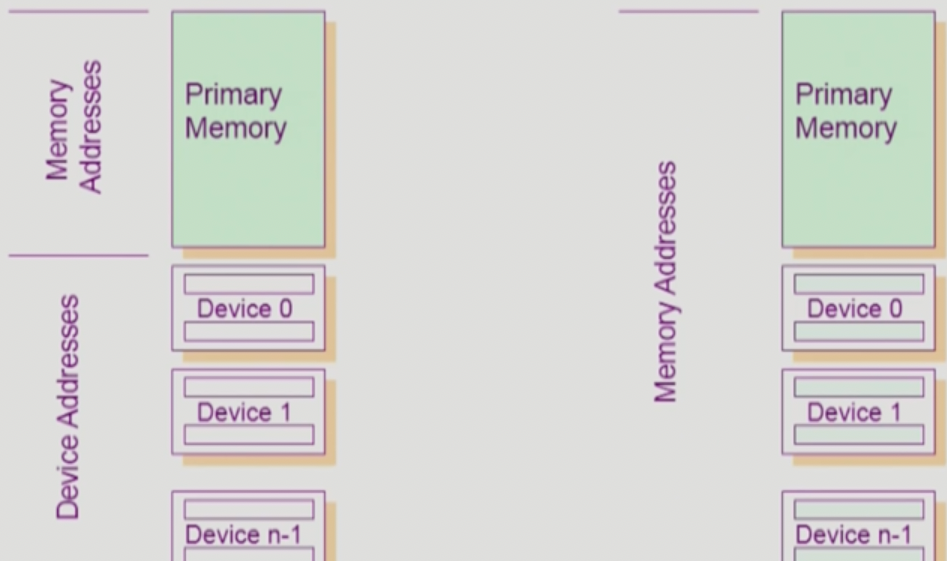
- IO를 하는 방법에는 두가지가 있는데
- 위 그림에서 왼쪽이 일반적인 상황으로 메모리에 접근하는 명령어와 디바이스에 접근하는 명령어(Special Instruction)가 별개로 존재하여 사용하는 방식과
- 오른쪽처럼 각 디바이스들을 메모리처럼 취급해서 확장 메모리 주소를 붙인 다음 메모리 접근 명령어를 그대로 사용하는 방식이 있다 → 이 방식을 Memory Mapped IO 라고 부르더라
Memory Hierarchy
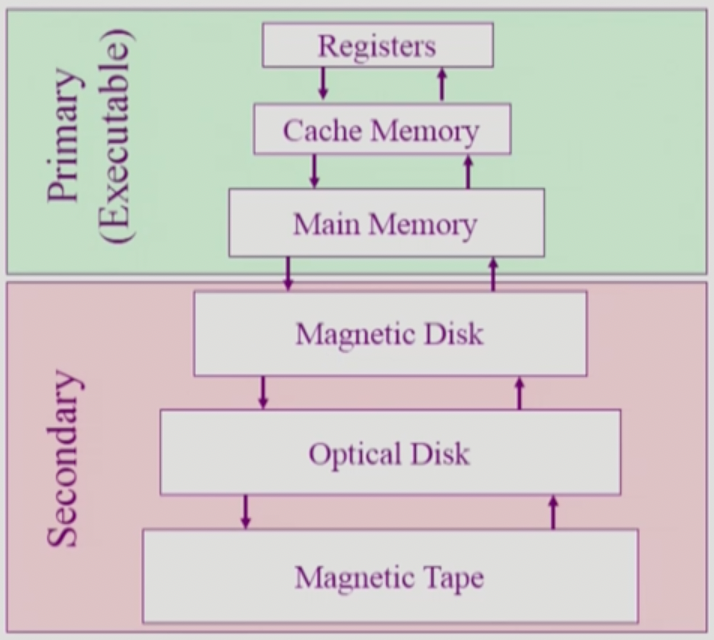
- Primary: 레지스터, 캐시(S-Memory), 램(DRAM) → 빠르고 비싸고 (따라서 용량이 작고) 휘발성이고 바이트단위로 접근이 가능해서 CPU가 실행시킬 수 있고 (Executable)
- Secondary: 느린 대신 싸고 (용량 크고) 비휘발성이고 바이트단위가 아닌 섹터 등의 단위로 접근할 수 있어서 CPU는 실행시킬 수 없다.
- 메모리에 접근하는것도 10개 정도의 Instruction이 소요되기에 이를 보완하기 위해 캐쉬 메모리를 두는거고
- 재사용의 목적으로 처음에 접근할때는 물론 오래 걸리지만 한번 접근해서 캐쉬에 올려놓고 나서는 그 다음부터는 아래까지 안내려가도 되기 때문에 훨씬 빠르게 사용할 수 있음 → 이런거를 캐싱이라 한댄다.
Program Execution
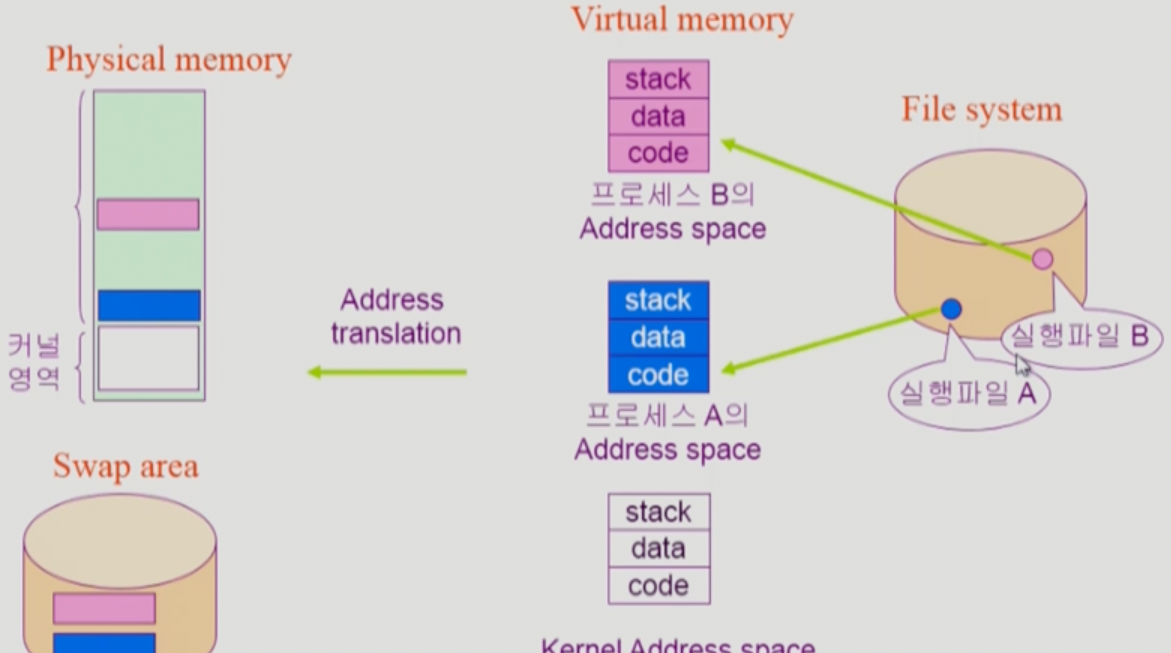
- 뭐 옛날에 배운것처럼 프로그램이 메모리에 올라가서 실행가능한 상태가 되었을때는 프로세스라고 하는데
- 메모리에 올라가기 전에 한 단계를 더 거친다 → Virtaul Memory 할당
- 이건 다음과 같은 식으로 이루어진다
- Virtual Address Space 할당 → 프로세스 하나마다 주소 0부터 시작하는 가상의 메모리 공간을 할당하고
- 이 가상 메모리 공간에는 많이 들어봤던 Code, data, heap-stack 이 드간다
- Address translation 을 통해서 가상 메모리 공간을 실제 메모리에 할당한다.
- 근데 가상 메모리 공간이 실제 메모리에 할당될때는 연속적인 공간에 할당되는게 아니고 쪼개서 당장 필요한것만 메모리에 올려놓고 나머지는 디스크의 Swap area 로 다시 내려놓았다가 사용할 일이 있으면 그때 가져오는 방식으로 작동함
- Virtual Address Space 할당 → 프로세스 하나마다 주소 0부터 시작하는 가상의 메모리 공간을 할당하고
Kernel
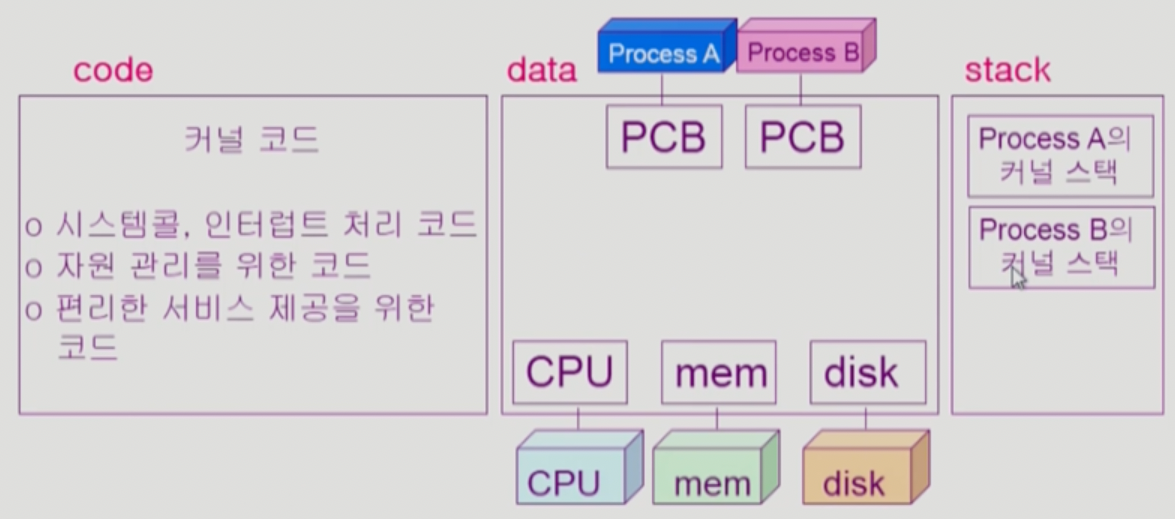
- Kernel 이 차지하는 메모리 공간도 당연히 Code, Data, Stack의 형태로 구성된다
- 뭐 Code 에는 자원 관리나 인터럽트 처리하는 코드 및 편의기능이 드가있고
- Data 에는 CPU, 메모리, 디스크를 관리하기 위한 자료구조들과 PCB가 적재된다
- 다음시간에 배우겠지만 프로세스가 하나 실행되면 해당 프로세스의 상태같은 제어정보를 담기 위한 자료구조가 하나씩 생성되며 이들을 PCB(Process Control Block)이라고 부른다.
- Stack에는 위 그림에서는 좀 헷갈리게 이름이 붙여져 있지만 결국에는 커널도 여러개의 함수로 구성되어있기 때문에 커널 함수가 실행될때마다 스택에 쌓이게 된다
- 즉, 어떤 프로세스가 어떤 함수를 호출하면 그때 스택에 ~프로세스가 호출한 ~함수 의 형식으로 스택이 쌓이게 되는 거다
- 따라서 커널은 프로세스별로 스택을 만들어서 특정 프로세스가 호출한 커널 함수 정보를 관리한다.
Functions
- 함수는 고급 언어 수준 뿐만 아니라 어셈블리어에서도 존재한다 → 어떤 언어로 코드를 작성해도 컴파일 이후에는 결국에는 걔네들이 다 함수형태로 바뀌게 된댄다
- 함수에는 세가지 분류가 있다
- 사용자 정의 함수: 말그대로 사용자가 정의한 함수
- 라이브러리 함수: 사용자가 정의한 게 아니고 다른 사람이 라이브러리로 만들어놓은 함수
- 라이브러리 함수도 당연히 컴파일 이후 바이너리에 함께 들어있게 되고
- 따라서 프로세스가 된 이후에 일반 프로세스의 Code 공간에 존재하게 된다.
- 커널 함수: 커널 프로그램의 함수
- 이 함수를 호출하는게 결국에는 Syscall 인거고
- Syscall 이 필요한 이유를 좀 다른 관점에서 보면 Virtual memory에서 Address space 는 프로세스마다 갖고 있고 Address jump는 해당 Address space 내에서만 가능하기 때문에 다른 Address space 에 속하는 커널 함수로는 점프할 수가 없어서 Syscall 이 필요한 거라고 볼 수도 있다.
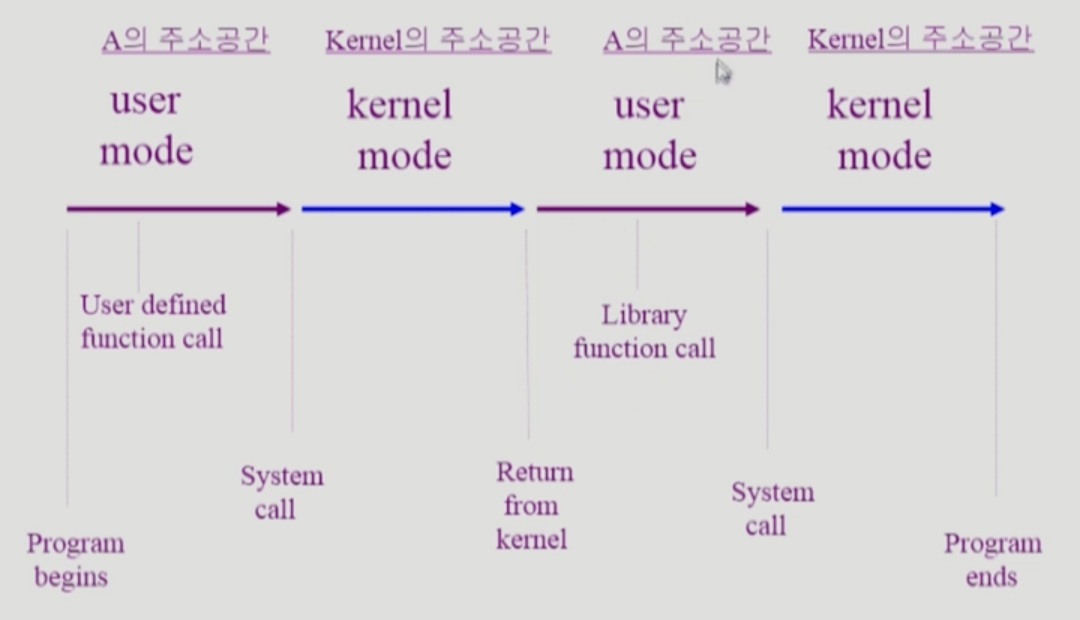
- 그래서 프로세스 하나와 커널과의 상호작용만 보면 (Time sharing 같은거 다 빼고)
- 사용자 함수나 라이브러리 함수가 실행될때는 해당 프로세스의 주소공간에서 User mode(Mode bit 1) 로 작동하다가
- Syscall이 발생하면 Kernel mode(Mode bit 0) 으로 변경되어 커널 함수가 실행되는 것이다.