서울대학교 컴퓨터공학과 김진수 교수님의 "고급 운영체제" 강의를 필기한 내용입니다.
다소 잘못된 내용과 구어적 표현 이 포함되어 있을 수 있습니다.
Benefits of Virtual Memory
- Transparency:
- Process 에게 쓰기 쉬운 abstraction 을 제공한다
- 즉, (실제로는 그렇지 않지만) process 에게 (1) 독점적인 (2) 큰 사이즈의 (3) 연속된 공간 이라고 뻥카치는 것.
- Efficiency
- 한정되어 있는 물리 메모리 공간을 디스크와 협력하며 (swapping) 효율적으로 사용할 수 있게 함
- 즉, 최대한 많은 프로세스가 최대한 적은 오버헤드로 한정된 메모리 공간을 공유할 수 있게 해준다.
- Protection
- 일반적인 HW 는 syscall 로 접근하는 것이 커널의 기본적인 protection 정책인데
- 메모리의 경우에는 이렇게 하면 느무나 오래 걸리기 때문에 그냥 접근할 수 있도록 뚫어놓은 것이고
- 이때의 protection 을 제공하기 위한 방법으로서 virtual memory 가 이점을 가진다.
- 구체적으로는
- CPU 가 메모리에 접근할 때 접근 권한에 대한 정보는 OS 가 갖고 있어서 CPU 와 OS 간의 협력이 필요한데
- 이 협력 수단으로써 virtual page 의 page table 이 사용된다.
- 이 page table 이 올바르다면, virtual memory address 로 접근할 수 있는 physical memory 공간은 독립되어 있기 때문에 다른 메모리 공간을 침범할 수 없는 것
Virtual Address Space (VAS)
- 뭐 흔히 보이는 code-data-heap-stack 그림이다:
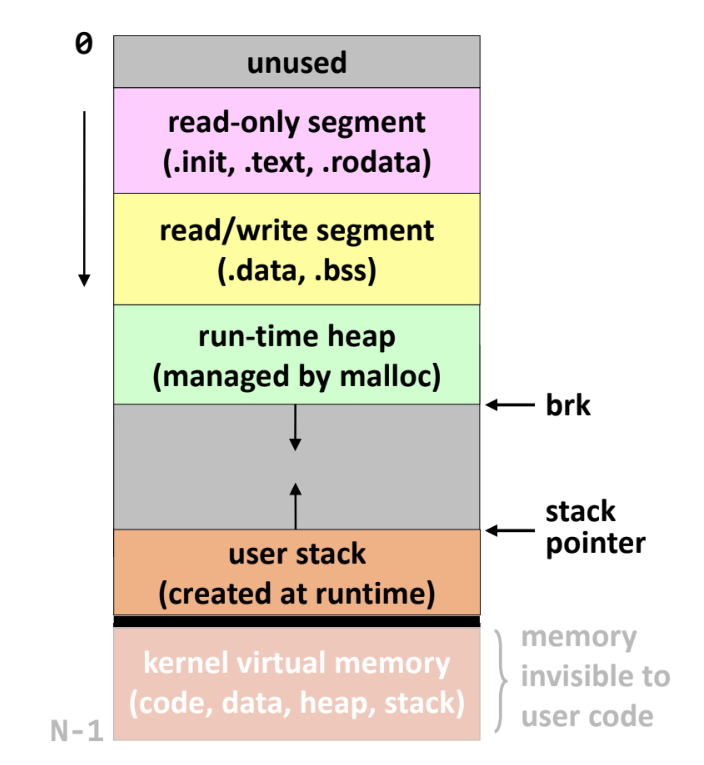
- 새로 알게된 내용만 정리해 보자:
- heap 의
malloc은 library 함수이고 syscall 이 아니다.malloc은 heap 공간을 갖고 장난치다가 여기에 공간이 부족해 지면sbrk라는 syscall 을 부르고 이때 heap 이 늘어나는 것
- 그리고 stack 아래에는 kernel memory space 가 있어서 kernel mode 로 진입하면 여기로 가게 된다.
- 옛날에는 kernel virtual memory 공간 전체가 다 붙어있어서 단순히 Virtual addr 를 bitwise operation 하는 것으로 여기로 진입할 수 있었다. (물론 kernel mode 라는 전제 하에.)
- 하지만 이제는 meltdown attack 라는 취약점이 발견되어 user VAS 공간에 kernel VAS 는 최소한만 남겨두고 완전히 분리시킨다고 한다.
- heap 의
Paging
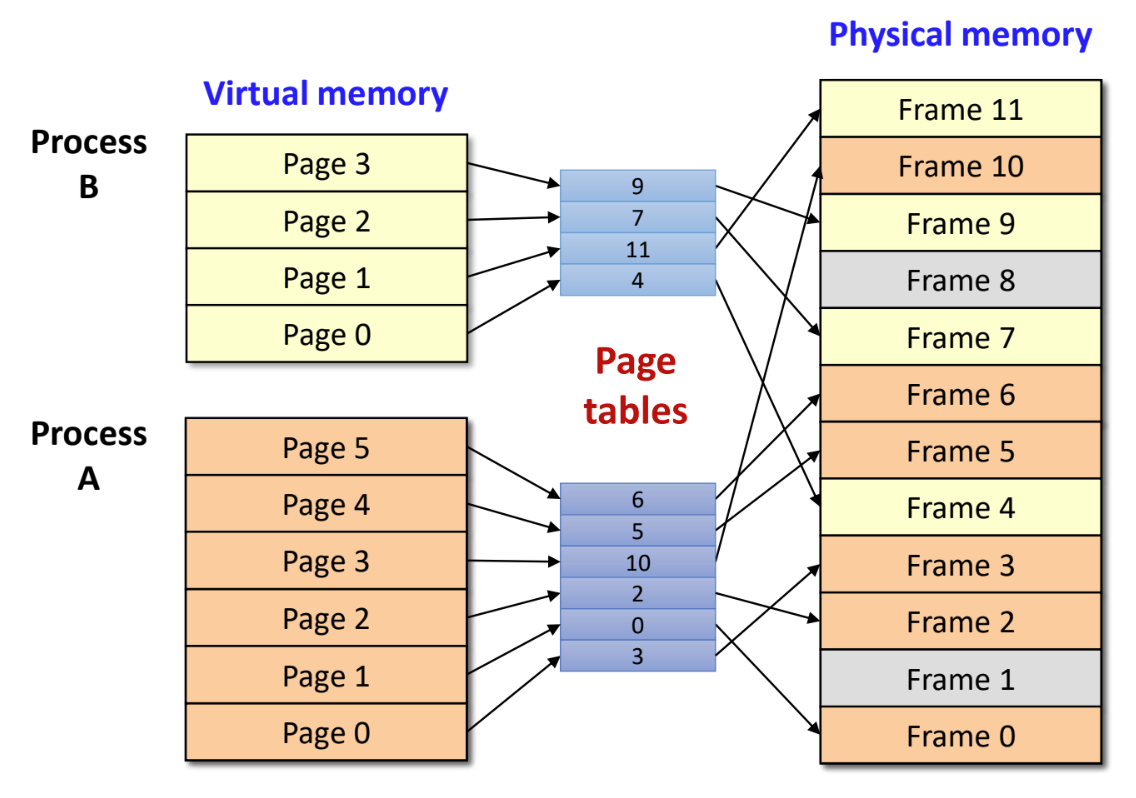
- 뭐 기본적인 것만 빠르게 짚고 가자:
- Paging 기법은 VAS 공간을 고정된 크기의 page (512byte ~ 8Ki… 보통 4Ki 인듯) 로 나누고 PAS 공간은 같은 크기의 frame 으로 나눈 다음 VAS 공간을 여러 frame 에 불연속적으로 매핑해서 사용한다는 것
- Free page 들은 OS 가 추적하여 VAS 에 할당
- Internal fragment 만 있고, external fragment 는 없다.
- 참고로 옛날에는 segment 같은것을 썼는데 지금은 paging 으로 평정되었다.
- 장점
- External frag 가 없다
- allocate, free 가 쉽다
- disk sector 사이즈의 배수이기 때문에 disk IO 도 좋다
- page 별 share, protection
- 단점
- Internal frag
- Page table 의 필요성
Page table
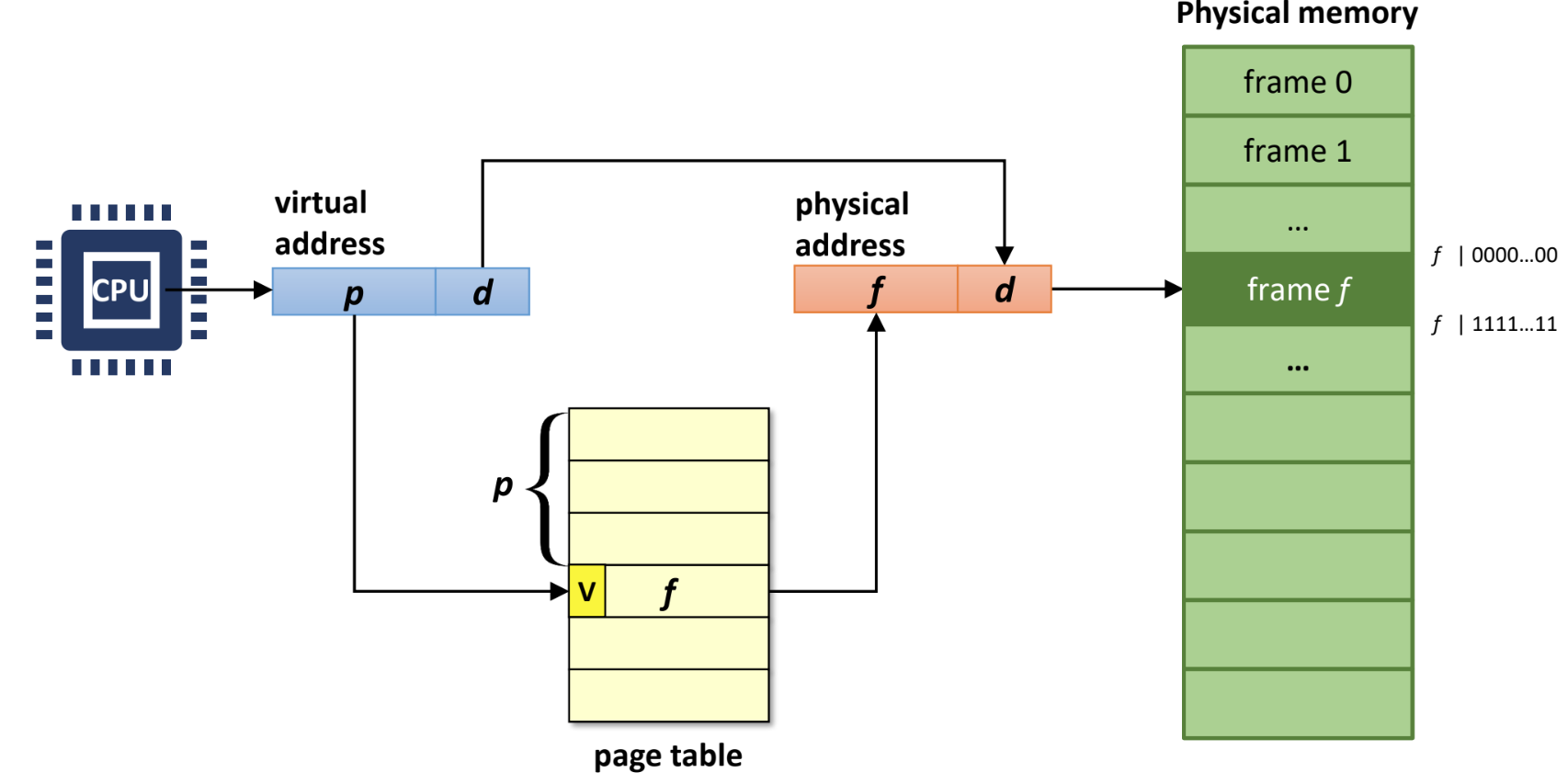
- 뭐 virtual page number (VPN) 에서 physical frame number (PFN) 으로의 변환이 page table 의 역할
- page 와 frame 내부에서의 위치인 offset 은 변하지 않음
- 뭐 다 기억나죠?
- 이 page table 을 만드는 것은 OS 이고 이것을 사용하는 것은 MMU 나 TLB 같은 HW 이다
- CPU 조차도 VA 를 사용하고, CPU 가 이 VA 를 원할 때 page table 을 이용해 자동으로 주소변환하는 놈이 MMU (Memory Management Unit) 이다.
- Page table 은 process 마다 있고, 이 process 가 scheduling 될 때 OS 가 한 레지스트리 (인텔의 경우
CR3) 에 page table 의 위치를 설정하며, 이CR3는 MMU 가 참조하여 주소 변환을 한다.

- Page Table Entry (PTE): 구조는 위 그림과 같다
- Valid bit (V): page table 에는 valid bit 가 있어서 이 값이 유효한지 확인한다
- 만일 유효하지 않다면 memory 에 올라오지 않은 것이고 따라서 page fault 가 발생
- Reference bit (R): 최근에 참조된 적이 있는지 (한번이라도 r/w 가 있었는지)
- 이 값을 이용해 evict 할 page 를 선정하는 것에 도움을 줄 수 있다
- Modify/dirty bit (M): 이 주소의 공간이 write 된 적이 있는지
- 이 값이 0 이면 변경되지 않았다는 뜻이기에 swap out 하지 않는다
- Prot: Protection attribute
- Valid bit (V): page table 에는 valid bit 가 있어서 이 값이 유효한지 확인한다
- Page table OS 와 CPU 의 소통 창구인 점을 생각하면, PTE 의 R 와 M 은 CPU 가 알고있는 정보를 OS 에게 알려주는 것이고 나머지는 반대라고 생각할 수 있다.
Demand paging
- Memory 를 VAS page 에 대한 cache 로 사용하며 필요할 때만 올리자는 것.
- physical memory 공간은 virtual memory 에서 access 되기 전까지는 alloc 하지 않는다
- page fault 가 발생해야 page fault handler 가 돌며 그제서야 특정 virtual addr 에 physical addr 가 할당되고, page table 에도 올라간다.
- 장점으로는
- IO 가 적고
- 메모리도 적게먹고 (따라서 더 많은 프로세스가 올라갈 수 있고)
- 프로세스 시작도 빨라지고 - code 를 전부 메모리에 올리기 보다는 첫 몇개의 페이지만 올리는 것이 더 빨리 끝나기 때문)
Page faults
- page fault 종류 - 이 모든 애들은 발생시 trap (page fault) 가 걸려 kernel 로 넘어가게 된다
Major page fault
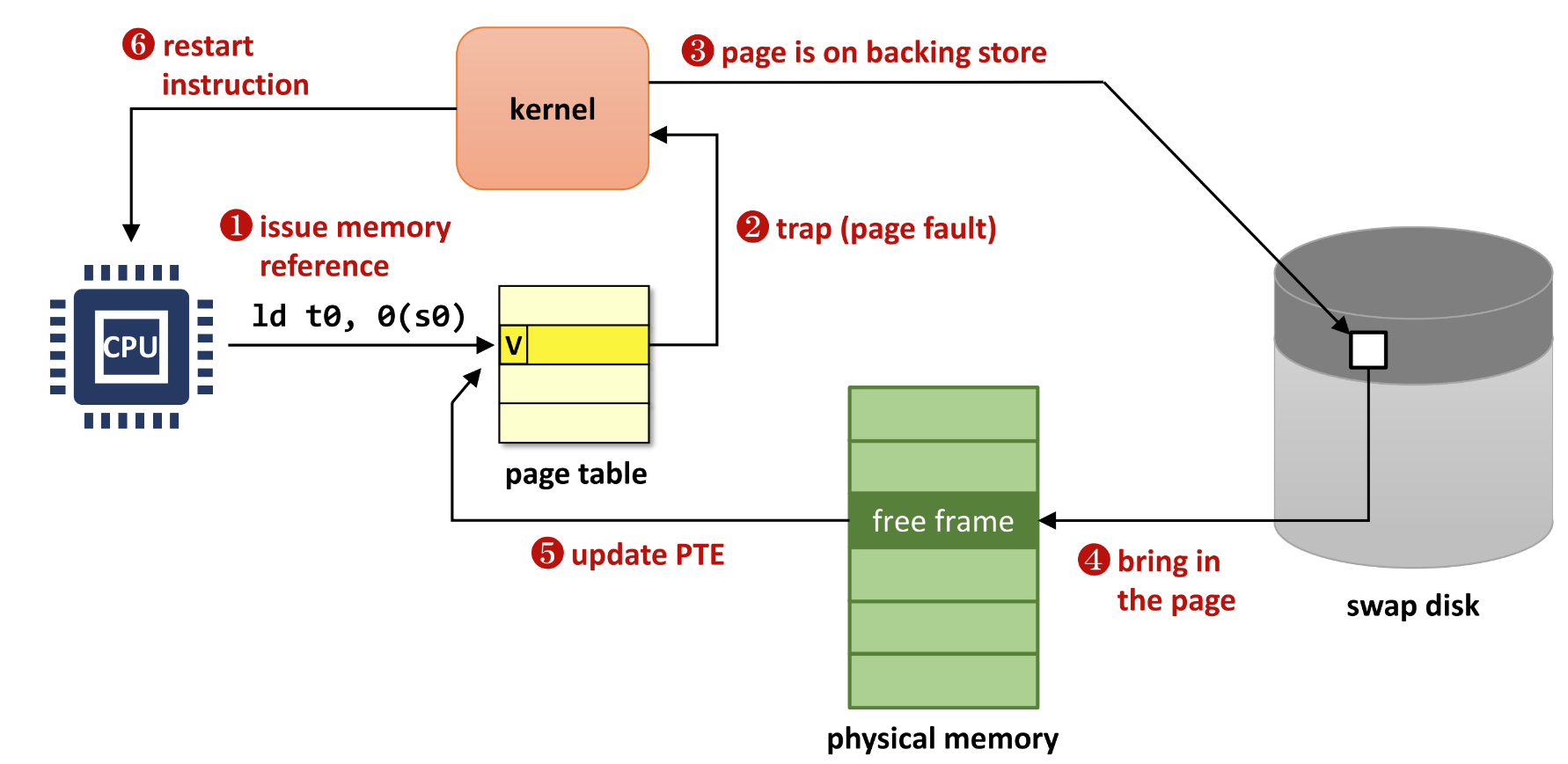
- IO 를 필요로 하는 page fault
- 따라서 IO 동안 process 를 block 하고 다른 process 를 돌리기 위해 context switching 이 필요하다.
Minor page fault
- IO 를 필요로 하지 않는 page fault
- 가령 anonymous page 들에 대한 page fault:
malloc같은 경우에는 disk 에 있는 것을 메모리로 올리는 것이 아닌 그냥 따끈따끈한 메모리 공간을 할당받는 것이기 때문에 IO 가 필요 없다 - 또는 한동안 사용하지 않아서 swap out 하기 위해 page cache 로 넘겼는데 그 직후 사용해서 그냥 page cache 에서만 가져오면 되는 경우도 여기에 해당한다.
Segment fault (violation)
- Page 가 VAS 범위를 넘어간 경우라고 하네
Multi-level page table
IA-32 (x86 32bit)
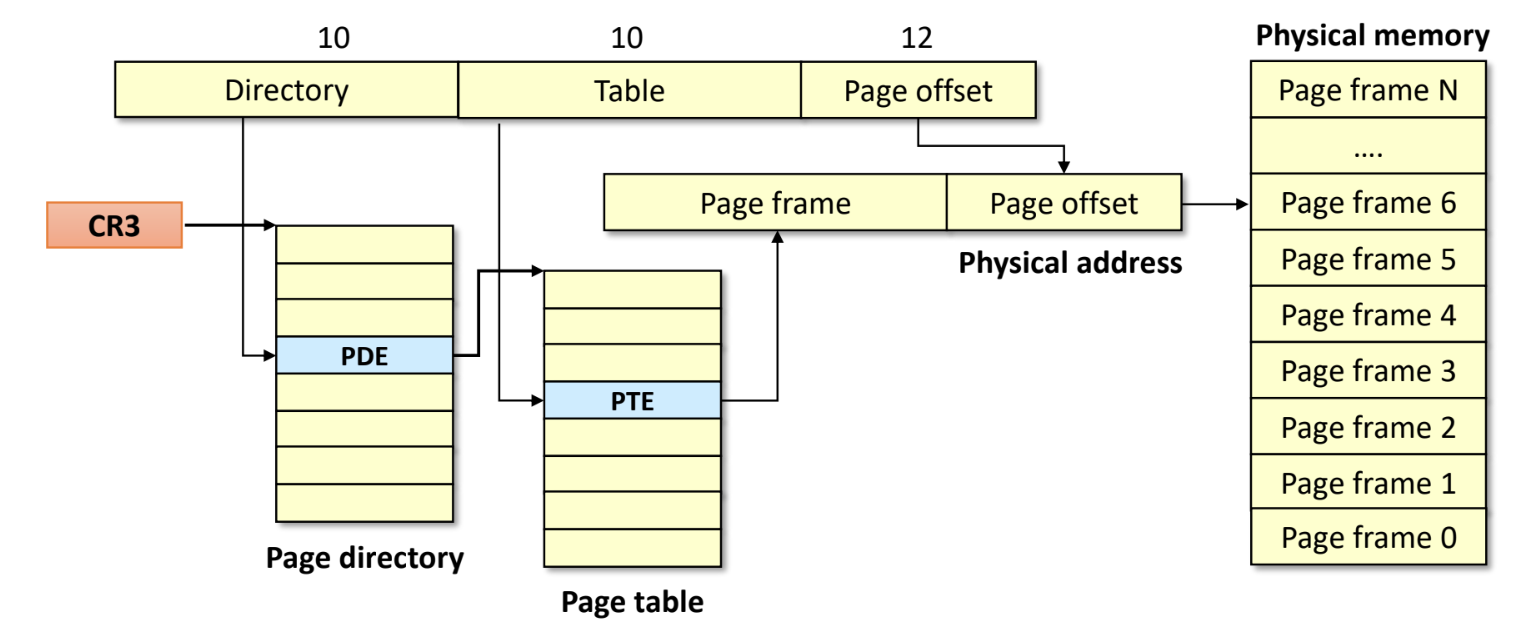
- 32 bit addrerss space 에서 offset 이 12 bit 면 나머지 20bit 가 virtual address number 가 되기에 page table 의 크기가 이 된다
- 그리고 이것은 공간을 많이 차지할 뿐 아니라
- 이 page table entry 중에서 실제로 사용하는 것은 (valid 한 것은) 얼마 안되기 때문에 낭비가 심하다
- 또한 이것을 hashing 으로 해결하려도 해도 cpuu 가 이런 hashing 을 수행하기 때문에 문제가 만타
- 따라서 10 bit 은 page directory number, 10 bit 은 page table number, 12 bit 은 page offset 으로 해서
- entry 를 가진 page directory 가 있고, 여기에도 validity 를 저장할 수 있어서 valid 한 경우에는 이놈의 자식인 page table 에 valid page table entry 가 적어도 하나는 있고 invalid 의 경우에는 전부 다 invalid 인 것
- 이러한 자료구조를 radix tree 라고 한다
- n 개의 자식을 가질 수 있을 때 각 자식에 대한 bit 를 가지고 있어서 bit 가 1 이면 해당 번째의 자식이 존재한다는 것
IA-32e (AMD64)
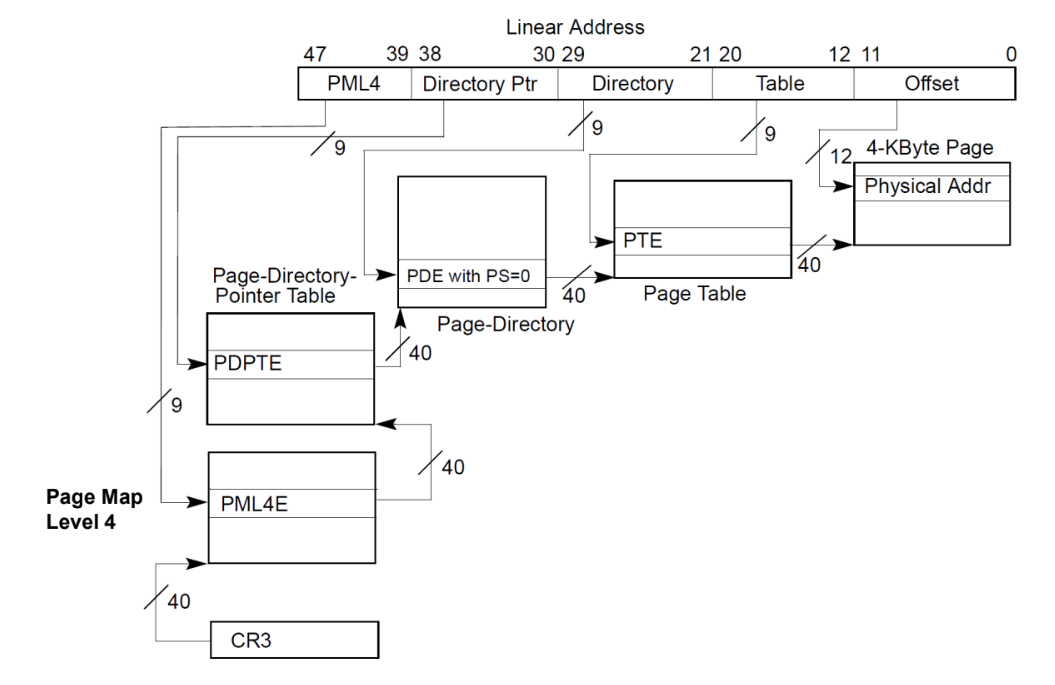
- 64 bit 운영체제에서는 48bit address system 을 사용하고
- (PML4
9bit)-(Directory Ptr9bit)-(Directory9bit)-(Table9bit)-(offset12bit) 의 구조이다 - page directory entry 하나의 경우 2MB 의 주소 공간을 표현하고 ()
- page directory ptr entry 하나의 경우 1GB 주소공간을 표현 ()
- (PML4
- 따라서 AMD64 arch 의 경우에는 2MB 와 1GB 의 superpage 를 제공한다
- 그래서 page table 하나를 통째로 사용하지 않고 page directory 가 직접 superpage 를 가리키게 한다.
- Intel icelake 부터는 5-level page table 을 사용한다고 한다… FYI
여기부터는
2024-05-16강의
TLB
- Translation Lookaside Buffer (TLB) CPU 내의 L1~3 cache 와는 별개로, MMU 안의 translation 을 위한 cache 이다.
Locality and miss rate
- Temporal locality: 지금 사용된 놈은 다음에 또 쓰일것이다
- Spatial locality: 지금 사용된 놈의 주변애들이 조만간 또 쓰일거다
- 일반 L1~3 같은 cache 에 비해 hit rate 가 훨씬 좋다 - 그래서 entry 가 작아도 있는것과 없는 것은 차이가 엄청 크다
- 이것은 왜냐면 frame 4K 에 대한 접근을 하나의 TLB entry 로 커버칠 수 있고
- 이것은 즉 그냥 메모리 공간에 대한 cache hit 에 비해 훨신 hit rate 를 높이게 된다
- 또한 이 점이 superpage 이 갖는 이점이기도 하다; superpage 의 경우에는 page 가 더 크기 때문에 더 많은 범위의 address translation 을 TLB entry 하나로 퉁치기 때문
- 보통 address 는 sequential 하게 접근되고 loop 도 있기 때문에 hit rate 가 개높다
- 이것은 왜냐면 frame 4K 에 대한 접근을 하나의 TLB entry 로 커버칠 수 있고
Entry count
- TLB 는 보통 16~256 entry 정도를 가지는데
- 한번에 lookup 하는 entry 개수에 대해서는
- Fully-associative: 모든 entry 를 한번에 lookup 함
- Set-associative: 일부 entry 만 함
- 이전에는 fully-associative 였는데 지금은 entry 가 많아지며 fully-associative 로 lookup 하는 것이 latency 있어 set-associative 로 작동한다고 한다.
Replacement Policy
- Replacement policy 는 LRU 를 근사한 A-LRU 를 사용한다
- 아무래도 page table 에는 reference bit 밖에 없으니까 몇번 reference 됐는지의 정보가 없어서 LRU 를 그대로는 사용하지 못하고 Approximate LRU 를 사용하는 것
TLB miss handling: SW vs HW
- TLB miss 시에는 SW 로 처리하거나 HW 로 처리하는 두가지 방법론이 있다.
- Software-managed: TLB miss 에 OS 가 개입함
- 이전에 MIPS (앵간한 것은 SW 로 처리하자) 에서 이렇게 했다
- 여기에서는 TLB miss 가 나면 trap 이 걸려 handler 가 불린다
- page table 의 구현이 자유롭다는 장점
- Hardware-managed: OS 개입 없이 hardware 가 처리
- 여기서는 HW 가 page table 을 뒤져서 TLB 에 올리기 때문에 page table format 이 HW 에 따라 고정되어 있다.
- 그래서 OS 는 이 format 에 맞춰 메모리에 page table 을 올리고 CR3 레지스터에 시작주소를 저장해서 HW 가 CR3 를 통해 page table 로 왔을 때 정해진 형식에 따라 처리될 수 있게 한다.
- 요즘은 이게 대세
Intel CR3 register
- Intel 의 CR3 (PTBR -Page Table Base Register) 레지스터는 page table 의 위치를 저장하는 곳이다.
- RISC-V 의 경우에는
satp라고 부른댄다.
- RISC-V 의 경우에는
- 이 값이 변경되면 자동으로 TLB 가 flush 된다.
- 여기서 flush 라는 것은 하위 스토리지로 내리는 것이 아닌 cache 를 비운다는 (삭제한다는) 의미
- 물론 모든 entry 를 삭제하는 것이 아니다 - 여러 process 들의 addr mapping 이 TLB 에 공존하기 때문에 실행중이었던 process 의 TLB entry 만 날려버림
- 심지어 같은 값을 write 해도 flush 된다 - 강제 flush 가능
- 일부 CPU 아키텍처에서는 특정 entry 가 flush 되지 않도록 flag 를 줄 수도 있다.
ASID (Address Space ID)
- TLB entry 에는 ASID (Address Space ID) 도 같이 붙인다.
- ASID 는 virtual addr 이 어느 process 의 VAS 인지 구분하기 위한 것.
- 그래서 CPU 가 TLB 를 뒤질 때 이 ASID 를 같이 붙여서 뒤진다
- 이 ASID 는 process 마다 할당되는데, PID 와 똑같지는 않고 간소화? 된 ID 이다.
- Intel 기준으로는 PCID (Process Context ID) 라고 한다
- Intel 의 PCID 는 12bit 을 ASID 체계를 사용하는데 실제 running 중인 process 가 이 4096 개를 넘을 수는 있지만 active 하게 running 되는 process 개수는 보통 이것보다는 작기 때문에 큰 문제가 안된다고 한다.
- 즉, 이것이 부족해지면 어떤 process 에게서 할당된 PCID 를 뺏어서 주고, 기존에 TLB 에 있던 해당 PCID 의 entry 들은 전부 flush 하는 것으로 쇼부본다.
TLB Coherence
- Multi core 의 경우에는 core 마다 존재하는 TLB 들 끼리 sync 가 안맞아 잘못된 작동을 할 수 있다.
- CPU cache 의 경우에는 이런 것을 방지하기 위해 HW 적으로 sync 를 맞추게 되는데
- TLB 의 경우에는 sync 하지 않는다.
- addr translation 에는 OS 가 끼어들지 않기 때문에 HW 적으로 sync 를 해야 될 것 같지만
- 그렇게 하지 않는 이유는:
- Page table 이 변경되어서 TLB entry 가 변경되었는데 다른 core 에서는 이것이 반영되지 않아 이 core 에서는 엉뚱한 곳을 참조하게 되는 것이 문제가 될 수 있다.
- 근데 이 page table 이 변경되는 것은 swap 과 같은 상황에서 발생하는데
- 이것이 자주 있는 일도 아니고 OS 가 전부 알고 있기 때문에 굳이 sync 를 맞추지 않는 것
TLB Coverage (TLB Reach)
- TLB 가 커버치는 physical memory 공간 크기를 의미한다.
- 당연히 이다.
- 이 TLB Coverage 를 늘리기 위한 방법으로
- entry 개수를 늘리기 위해서 multi level TLB 를 사용하기도 한다.
- 가령 Intel haswell 의 경우에는 L3 (L1 ITLB, L1 DTLB, L2 STLB) 로 세단계로 하기도 함
- Page size 를 늘리는 방법이 superpage, hugepage 이다.
- entry 개수를 늘리기 위해서 multi level TLB 를 사용하기도 한다.
- 또는 개발을 할 때 TLB 에 맞게 최적화 된 알고리즘이나 자료구조를 선택하는 방법도 있다고 하더라..