서울대학교 컴퓨터공학과 김진수 교수님의 "고급 운영체제" 강의를 필기한 내용입니다.
다소 잘못된 내용과 구어적 표현 이 포함되어 있을 수 있습니다.
SSD 에 대한 조금 더 추가적인 내용들..
- Filesystem in Userspace (fuse): fs 를 잠시 user space 에 빌려줘서 user space 에서 fs 조작을 할 수 있게 하는 것?

- HDD 와 SSD 의 차이점
- IO 성능 만 볼 때, sequential 이 HDD는 더 빠르나 SSD 는 딱히 그렇지도 않다.
- 이 HDD 에서의 sequential 이 더 빠르다는 것을 활용한 것이 LFS 이다.
- SSD 에서 sequential 이 더 좋다 라고 하는 것은 IO 자체의 성능보다는 GC overhead 때문인 것.
- SSD 에서만 WAF 가 있다
- HDD 에서는 background 작업이 적어서 성능이 일관되게 나타난다
- SSD 에서는 대표적인 적폐 GC 가 background 로 돌기 때문에 아무래도,,
- SSD 에서는 wear 가 있다.
- SSD 는 저장 위치의 차이가 성능의 차이를 갖고오지는 않는다
- HDD 에서는 당연히 있다; FFS 가 이러한 특징을 잘 파고든 filesystem 인 것.
- IO 성능 만 볼 때, sequential 이 HDD는 더 빠르나 SSD 는 딱히 그렇지도 않다.
- FTL 의 계층들
- Sector translation layer:
- Address mapping
- GC 수행
- Block management layer
- Bad block 교체나
- ECC 등 수행
- Low level driver
- 옛날 삼성에서 사용하던 용어
- Channel 로 flash 에 명령어 날리는 작업 등인듯
- Sector translation layer:
TRIM- 파일이 삭제되면 directory entry, directory inode, inode bitmap 등이 변경됨
- Inode 는 안고쳐도 되냐… inode 는 변경되는게 아니라 삭제된단다.
- 즉, 파일 삭제는 fs 에서 metadata 를 바꾸는 것으로 처리하고 data block 은 바뀌는게 없기 때문에 ssd 가 이 파일이 지워졌다는 것은 해당 block 에 overwrite 가 발생했을 때에만 알게 된다
- 따라서 이 기간 중에는 ftl 은 데이터가 살아있는 것으로 알고 있음
- 살아있다고 알고 있다는 것은 GC 할 때도 갖고다니는게 문제다.
- 그래서
TRIMcommand 가 나오게 된것 (혹은discard,deallocate) - 여기서는 sector 번호를 알려주며 여기 있는 것들은 다 지워졌다고 ssd 에게 알려주게 되는 것
- ubuntu 등에서는
fstrimdaemon 이 있어서 주기적으로 밤마다 trim 을 해주기도 한다더라
- 파일이 삭제되면 directory entry, directory inode, inode bitmap 등이 변경됨
여기부터는
2024-04-18강의
IDENTIFY- 처음에 장치가 인식되면 OS 에서는 장치에 IDENTIFY 명령어를 날려서 장치에 대한 정보를 받아온다
- 그리고 이때 장치가 SSD 라면 그제서야 TRIM 명령어를 사용할 수 있는 것
Multi-streamed SSD
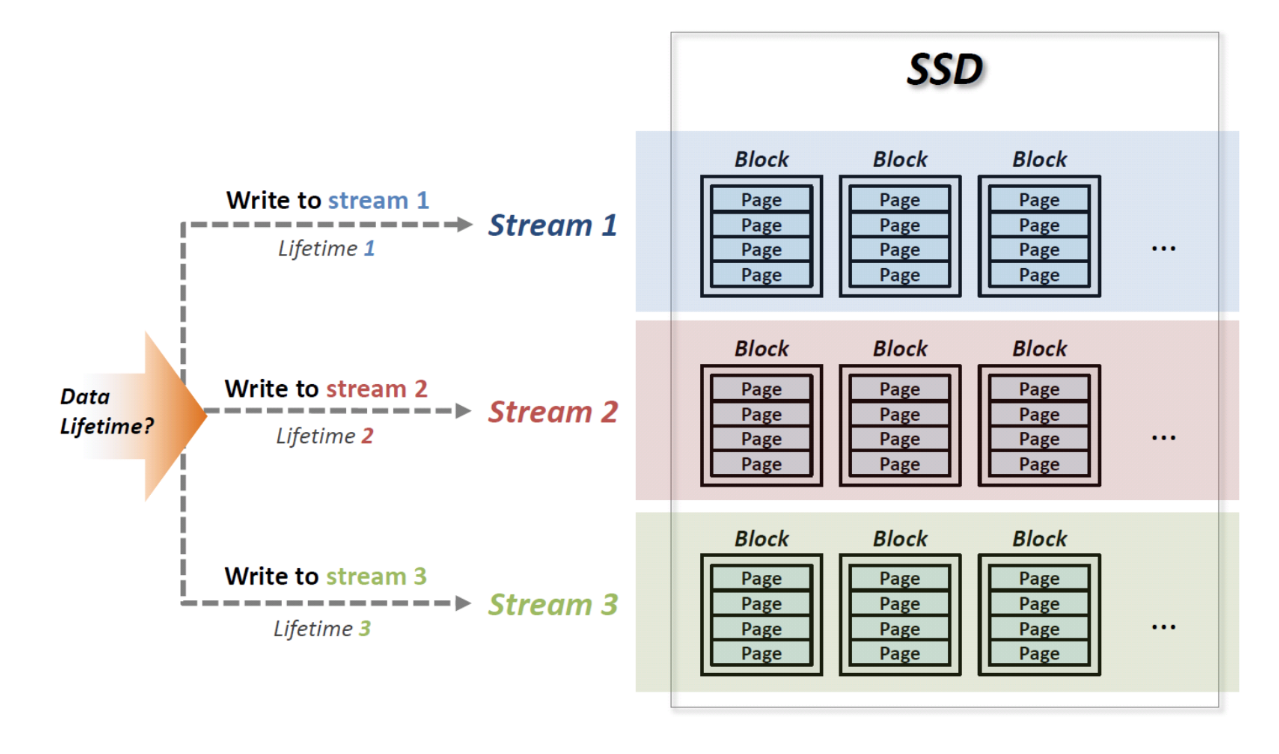
- 기본적인 사고흐름은 다음과 같다:
- 하나의 Physical Block (PB) 에 있는 내용이 한번에 죽으면 GC 오버헤드가 줄어들 수 있을 것이다.
- 그래서 lifetime 이 비슷한 애들끼리 모아서 PB 에 넣자는 아이디어
- sequential write 는 별로 도움이 안된다; lifetime 이 더 중요하다
- 근데 이 lifetime 을 device 에서는 알기 힘들기 때문에 이것을 host 한테서 힌트를 받자
- 이 힌트가 Stream 이다.
- CS 에서는 level of abstraction, 계층화 구조가 중요하다
- 각 계층은 독립적이고 다른 계층에서 하는 일을 알지 못하게
- 그리고 이 계층에서는 자기가 직접 알아서 잘 하거나 아니면 다른 계층으로부터 힌트를 제공받거나 해야 하고
- 이 힌트를 받자는 입장의 SSD 가 multi stream ssd 인 것
- 그래서 multi-stream SSD 는 다음과 같이 사용한다.
- 기존에는 sector addr 와 데이터 길이 정도로 write 를 수행했었는데
- 이제는 write 를 할 때에 lifetime 이 비스무리한 애들에게는 같은 stream number 를 부여할 수 있도록 하고
- Stream number 가 같은 애들은 같은 PB 에 저장된다.
- 원래는 application 에서 stream number 를 명시하게 할 생각이었으나
- 이것은 application 의 코드를 전부 바꿔야 하기 때문에 너무 힘들다 (write command 마다 id 를 명시해야 하기 때문에)
- POSIX interface 를 다 바꿔야 하는 등
- 그래서 타협한 것이 file 별로 stream 을 지정할 수 있게 한 것이다
- 이것은 POSIX 표준에 추가되어서
fadvise로 inode 에 stream id 를 추가할 수 있게 했다. - 이것을 명시 안하면 그냥 unique id 가 붙는다고 한다.
- #draft 더블체크 필요함; application 에서 file descriptor 에
fadvice로 명시하는 것 아닌가?
- 이것은 POSIX 표준에 추가되어서
- 이것은 application 의 코드를 전부 바꿔야 하기 때문에 너무 힘들다 (write command 마다 id 를 명시해야 하기 때문에)
Case Study: cassandra
- Cassandra 에서도 LSM 을 사용하기에 얼추 RocksDB 와 구조가 유사하다.
- 이놈을 사용할 때에는 다음과 같은 write 가 있을 수 있다고 한다.
- Memtable 에서 flush 되는 데이터
- write request 를 받았을 때 적는 commit log
- 참고로 write 시에 memtable 과 commit log 둘 다에 적힌다고 한다.
- Compaction 에서 수반되는 write
- (Cassandra 에서 write 하는 것은 아니지만) 시스템 data write
- 위와 같은 상황에서 다음과 같이 stream 을 분리해 볼 수 있다.
- 아무것도 분리 안하기
- Cassandra data (1~3) / System data (4) 분리하기
- 위 2번 상황에서 Cassandra commit log (2) 도 분리하기
- 위 3번 상황에서 각 level 의 compaction (3) 에 대해 level 마다 stream id 분리하기
- SST 들을 한번에 invalidate 시키는 방법?
- 위 4가지 방법이 있고 모두 적용했더니 좋더라 - 궁금하면 논문의 evaluation 참고하자
문제점
- Stream 의 갯수가 결국에는 active block 의 갯수이기 때문에
- stream 이 많아지면 그만큼 다 채워지지 않은 block 의 갯수도 많아지게 되어 utilization 의 문제가 있다.
- Buffer 개수 문제가 있다
- 데이터를 write 할 때에는 striping 을 해서 여러 plane 에 분배하는데
- 이때 각 plane 마다 buffer 를 두고 이 buffer 들이 모두 채워지면 cell 에 반영한다.
- 이전에는 그냥 buffer 가 채워지면 반영하면 됐었는데
- 이제는 stream 이 분리가 되어 있으니까 stream buffer 가 다 안채워지고 마냥 기다릴 수도 없고 그런식이다
- 그리고 이 buffer 들이 모두 dram 이기 때문에 buffer 를 무한정 늘릴 수도 없는 노릇
ZNS SSD
- 기본 아이디어는 OCSSD 처럼 음청 많은 권한을 host 에게 주고 너네가 알아서 GC 도 하고 너 다 해라 그냥
- 그리고 block interface 가 아닌 ssd 에 특화된 interface 를 만들자는 생각
- 대강 선행 기술들은 다음과 같다
- SDF (Software Defined Flash) - ASPLOS ‘14
- 하나의 ssd 의 여러 channel 들을 host 에서는 마치 하나의 ssd device 처럼 보이게 하고
- Page size 등의 정보도 host 에 줘서 알아서 관리하게 하는 방법인듯
- OCSSD 1.2, 2.0 - FAST ‘17
- Host 가 모든 것을 관장
- FTL 이 없고, data placement, gc 등 모든 것을 host 가 수행
- 여기서는 Physical Page, Physical Block, die, plane 등을 abstract 로 모두 host 에 공개하여 host 가 컨트롤하게 함
- 그래서 application 에서 이런 모든 것을 할 수 있으니까 좋겠다 라고 생각할 수 있었으나
- 문제는 flash error 를 핸들링하는 것은 결국에는 ftl 에서 해야 하니까 모든 것을 host 에서 할 수는 없고 ftl 이 필요하긴 하다는 결론이 났다.
- SDF (Software Defined Flash) - ASPLOS ‘14
- ZNS SSD
- 기존에는 SSD 제조업체가 proposal 을 했다면 이것부터는 hyperscaler (meta 처럼) 이 제안하게 된다.
- 즉, application 기업이 실 사용자 입장에서 제안한 것.
- 여기서는 flash error 같은 것은 FTL 에서 (ocssd 2.0 도 FTL 에서 하긴 하는듯)
- ZNS 는 기존 SMR HDD 를 위한 인터페이스가 이미 있으니 이것을 기준으로 새로 SSD 인터페이스 를 만들자 라는 생각
- Sequential write 만 가능한 zone 단위로 SSD 가 관리된다.
- Striping 해서 zone 크기를 늘린 large zone 과 작은 크기의 small zone
- Zone 을 erase 하는
resetAPI 가 있어 host 가 직접 데이터를 옮기고reset하는 host-driven GC 가 수행된다. - 그리고 이러한 sequential 한 특성과 host 가 관리한다는 측면 때문에 page mapping 이 아닌 block mapping 을 사용할 수 있어 DRAM 사이즈도 줄인다.
- Bad block 교체 등의 flash error 만 ftl 에서 해주면 되도록
- Application 에서 직접 zone 들에 접근하는 zoned raw block access 하거나, application 에서 약간의 fs 의 도움을 받을 수 있는 zone fs (zenfs?) 를 활용하거나
- 아니면 zns fully support 되는 fs 를 사용하거나
- 여기서 f2fs 가 또 나온다. ZNS 지원한다더라.
- 인터페이스를 block interface 스럽게 바꾸는 dm-zoned 를 사용해 (마치 애플 로제타처럼) 기존의 fs 를 돌릴 수도 있다.
- 위 두 fs 는 성능향상보다는 compliant 가 초점
- 기존에는 SSD 제조업체가 proposal 을 했다면 이것부터는 hyperscaler (meta 처럼) 이 제안하게 된다.
- ZNS SSD 장점
- application 이 많은 것을 control 해 GC overhead 줄임
- ZNS SSD 의 단점 - 요즘 zns 가 그닥 많이 쓰지 않는 이유
- Host 가 zone 에 sequential 하게 깔끔하게 쓰고 깔끔하게 한번에 지우는 것… 이 생각보다 어렵더라
- CPU core 마다 NVMe queue 가 있으니까 application 이 한 core 에서 돌다가 다른 core 로 가면 그쪽 NVMe queue 로 옮겨가기 때문에 sequential 이 잘 안됨
- 그리고 device error 가 나면 write 를 retry 해야 하고 이런 과정에서도 sequential 이 잘 안지켜지더라
- 또는 page cache 를 사용했을 때 순서가 섞이거나
- 이런 상황을 막기 위해 zone lock 을 거는 방법 등이 나왔는데 이것을 사용하면 또 bandwidth 가 떨어진다
- 그리고 이때 sequential 이 잘 안될 것 같을 때에 일단 쓰고 어디에 썼는지 쓴 다음에 알려주는 append (논문 nameless write 에서 제시됨) 명령어가 있으나
- 이것을 사용하기 위해서는 application 을 너무 많이 바꿔야 하는 등의 문제
- Host 가 zone 에 sequential 하게 깔끔하게 쓰고 깔끔하게 한번에 지우는 것… 이 생각보다 어렵더라
- 그래서 multi stream 의 업그레이드 버전인 fdp 등이 나오게 된다.
Key-value SSD (KVSSD)
- 기존의 block interface 의 LBA 는 주차장과 같다.
- 중간중간 빵꾸뚫여있고
- 비어있는 자리에 알아서 잘 주차해야 하는
- 근데 KVSSD 는 발렛파킹과 같다.
- SSD 가 알아서 잘 주차를 하고
- 나중에 host 가 key 만 던져주면 차를 알아서 잘 찾아서 가져오는
- 이 상황에서는 굳이 fs 도 필요 없다
- KV 는 block chain, ai/ml 등의 분야에서까지 범용적으로 사용되니까 device 에서 이것을 제공해주면 좋겠노
- device 위에 fs 올리고 KV storage backend 올리는 등 하는게 너무 비효율적이다…
- 그리고 device 내에서는 block interface 에 걸려 아무런 정보가 없는 상태인데 kv iface 정도가 되면 어느 key 의 data 가 어디에 있는지 다 device 에서 알기때문에 device 딴에서 더 많은 것이 가능할 것이라는 계산
- NVMe 에도 이러한 command set 이 들어갔다
- 기본적으로 hash indexing 을 사용한다
- rocksdb 와 비교했을 때 아주 좋지만 이것도 결국에는 상용화는 안됐다
- ssd 자체만 보면 그냥 ssd 보다는 느리다
- 하지만 이놈의 경쟁은 ssd 가 아니고 같은 kvstore 인 rocksdb 였고, 이거에 비해서는 더 좋았지만…
- 어쨋든 rocksdb 와의 경쟁에서 밀린 이유는 기능이 너무 빈약하기 때문
- get/put 만 가능하기 때문에 range query, transaction (ACID), snapshot 등의 기능이 불가능
- 하지만 get/put 만 좀 더 빠르게 해주는 것으로는 기능이 너무 부족해서 결국에는 사장
- crash recovery 도 문제였다 - put 중에의 crash 를 막기 위해 vesioning 을 두면 또 이것을 위한 무언가를 추가해야 하는 등
Computational Storage (Smart SSD)
- SSD 가 데이터 입출력 뿐 아니라 연산또한 하게 하자
- 이를 위해 SSD 에 FPGA 나 multi-core ARM CPU, NPU 등을 추가하게 된다.
- FPGA 말고 CGRA 를 사용할 수도 있을까?
- SNIA 라는 기관에서 추진중이라 한다
- NGD Newport SSD 에서는 OS + docker 도 돌릴 수 있다
- 하지만 결국에는 host 에서의 fs 가 걸림돌이 된다고 한다
- 이런 fs 의 문제를 하기 위해 tcp 를 넣어서 tcp over pcie 과 같은 짓도 한다고 한다
- 아쉽게도 NGD 는 2023년에 망했다고 한다
- tp 4091 - nvme 표준 제안
- 이정도로 비유할 수 있다
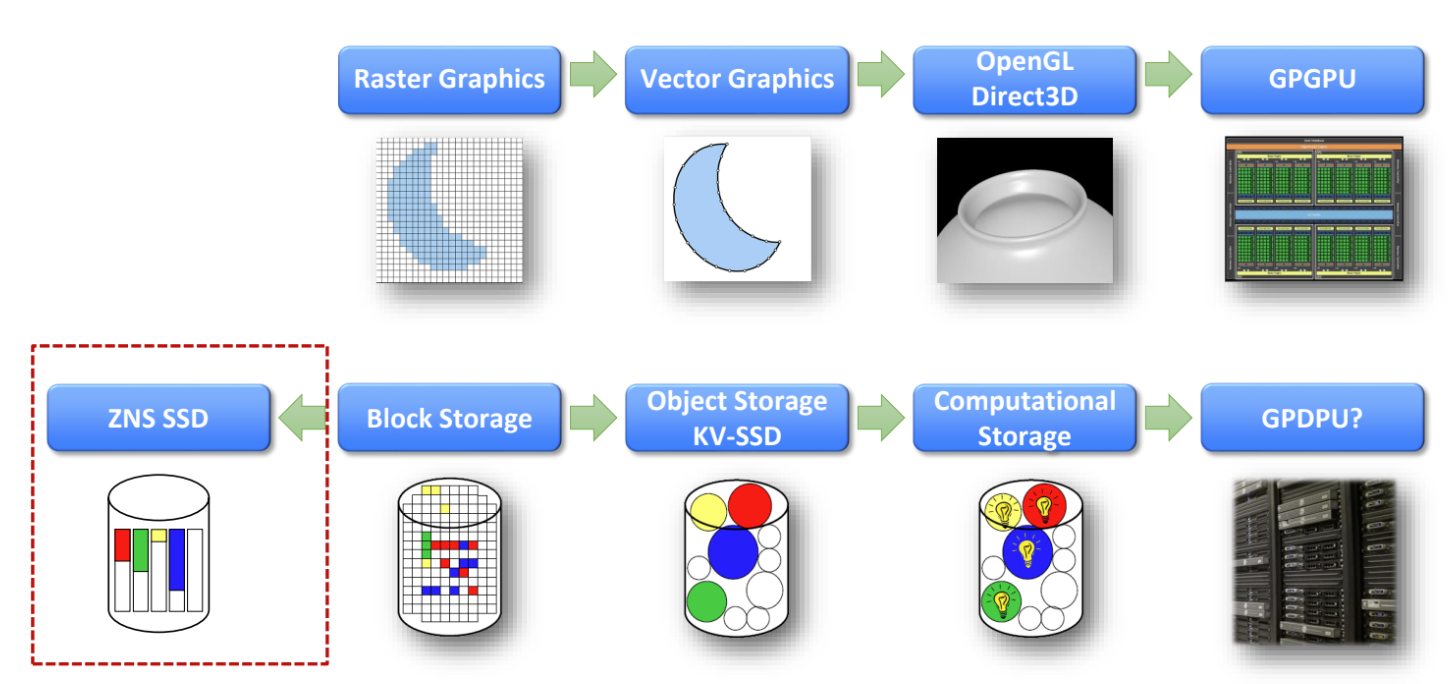
- raster graphic - block interface
- vector graphic - obj storage, kvssd
- 3d, opengl, direct3d - computational storage
- zns 는 block interface 보다 더 뒤로 갔다