본 글은 A comprehensive survey on DNS tunnel detection 를 읽고 정리한 글입니다.
별도의 명시가 없는 한, 그림들은 본 논문에서 가져왔습니다.
본 글은 #draft 상태입니다.
- Section 1~4.1 정리하기
1. Abstract & Introduction
#draft 나중에 정리할 예정입니다.
2. Background Information
2.3. DNS tunnels
2.3.1 Working principles
Direct connected DNS tunneling
#draft 나중에 정리할 예정입니다.
3. Analysis of behavior-based feature of DNS tunnels
- 간략하게 말하자면
- Payload anaysis 는 하나 이상의 dns packet 의 payload 에 대해 static analysis 를 하는 것이다.
- 뭐 subdomain 에 특정 단어가 들어가는지 등
- Traffic analysis 는 일정 기간의 모든 dns packet 이용해 트래픽 관점에서 분석하는 것이다.
- 뭐 특정 domain 에 대해 query 가 몰리는 등
3.1. Payload-based feature analysis
- 위에서 말한 것처럼, dns packet 을 static analysis 하는 것을 Payload analysis 라고 한다
Statistical analysis
- 먼저 dns tunneling 에 사용되는 packet 의 크기에 대한 특징을 살펴보자.
- 일반적으로 dns tunneling 의 query packet 은 사용자의 데이터를 빼내는 용도로 사용되기 때문에 사이즈가 크다.
- 당연하다; 최대한 많은 데이터를 한번에 보낼수록 throughput 이 좋아지기 때문.
- 반면에 dns tunneling 의 response packet 은 attacker 가 victim 에게 보내는 지령 (command) 만이 들어가기 때문에 일반 dns response packet 보다 사이즈가 작다.
- 일반 dns response packet 의 경우에는 여러 dns record 들을 응답하기 때문.
(1) Packet size
- 이러한 성질을 활용하여 사이즈가 큰 dns query packet 에 알람을 걸어 놓으면 tunneling detection 에 도움이 된다.
- 하지만 attacker 는 이것을 피하기 위해 thoughput 을 좀 손해보더라도 packet size 를 줄이되 dns query 를 더욱 많이 하는 선택을 할 수도 있다.
- 그러나 이렇게 dns query 를 늘리는 것은 또 트래픽 증가를 야기하기에 monitoring 과정에서 걸릴 가능성이 높아지기에, attacker 입장에서는 꽤 난감한 상황이 되는 것.
(2) Upload & Download ratio
- 위에서 말한 것처럼 dns tunneling upload (query) packet 사이즈는 normal query packet 사이즈에 비해 상대적으로 크고, dns tunneling download (response) packet 사이즈는 normal query packet 사이즈에 비해 상대적으로 작기 때문에
- Query size 와 response size 의 비율을 이용하여 dns tunneling detection 을 할 수도 있다.
Domain name analysis
- DNS 라는 것을 도입한 것 자체가 “IP 를 외우기 힘들어서” 이기 때문에 가독성이 좋은 영단어 등으로 domain 을 구성하는 것이 일반적이다.
- 하지만 dns tunneling 에 사용되는 domain 의 경우에는 데이터를 encoding 한 것이기 때문에, 보통 가독성이 좋지 않다.
- 물론 뭐 readability 가 좋게 encoding 하는 것도 가능하긴 하지만, 이러한 dns tunneling 방식은 아직까지 발견되지 않았다고 한다.
- 가령 01010101 bit 에 대해서는 KFC 로 encoding 하는 식으로 8bit 를 하나의 영단어에 매칭시키는 방법이 가능하겠지만
- 그러면 transmit throughput 이 아마 안좋아져서 이렇게 안하지 않나
(1) Domain, Subdomain length
- 어찌보면 Packet size 와 유사한 내용인데, dns tunneling 에서는 subdomain 에 encoded data 를 넣기 때문에 domain (subdomain) 의 길이가 자연스레 길어진다.
(2) Number of subdomains or labels
- 이것도 어찌보면 Packet size 와 연관된 내용이다; Subdomain label 의 길이는 최대 63byte 를 가질 수 있기 때문에, dns tunneling 에서는 이보다 더 큰 사이즈의 데이터를 보내기 위해 label 을 여러개 사용한다.
(3) The ratio of the longest meaningful substring/word’s length in the domain name
- Domain 의 readability 와 직접적으로 연관된 내용이다; domain name 에서 의미가 있는 (아마 사전에 등재된) word (substring) 의 비율이다.
- 당연히 일반적인 domain 의 경우에는 의미가 있는 word 들이 많이 포함될 것이기에 이 비율이 높을 것이고, tunneling 의 경우에는 encoded data 이기에 이 비율이 낮아지게 될 것.
- 그래서 우선 domain name 에서 가장 긴 의미가 있는 word (substring) 를 찾고, 그것의 길이를 전체 domain name 의 길이로 나눠 의미있는 문자열의 비중을 구한다.
(4) Character entropy
- 이것은 각 문자들의 사용 빈도를 이용해 readable string 과 그렇지 않은 것을 구분하는 방법이다.
- 일반적인 readable string 의 경우에는 자주 사용되는 문자가 있고 아닌게 있다.
- 가령 위키피디아 에 따르면 알파벳 E 는 사전에 등재된 단어 중 11% 를 차지하며 가장 많은 사용 빈도를 보여주는 반면 알파벳 Q 는 0.19% 로 가장 낮은 빈도를 보여준다.
- 하지만 tunneling 에 사용되는 domain 은 encoded data 이기 때문에 각 알파벳들의 사용 빈도가 다소 균등하게 나타난다.
- 이러한 특징을 이용하면 dns tunneling detection 을 할 수 있다.
Etc.
(1) Uncommon record types
- DNS record 들은 자주 사용되는 record type 이 있고 그렇지 않은 것이 있다.
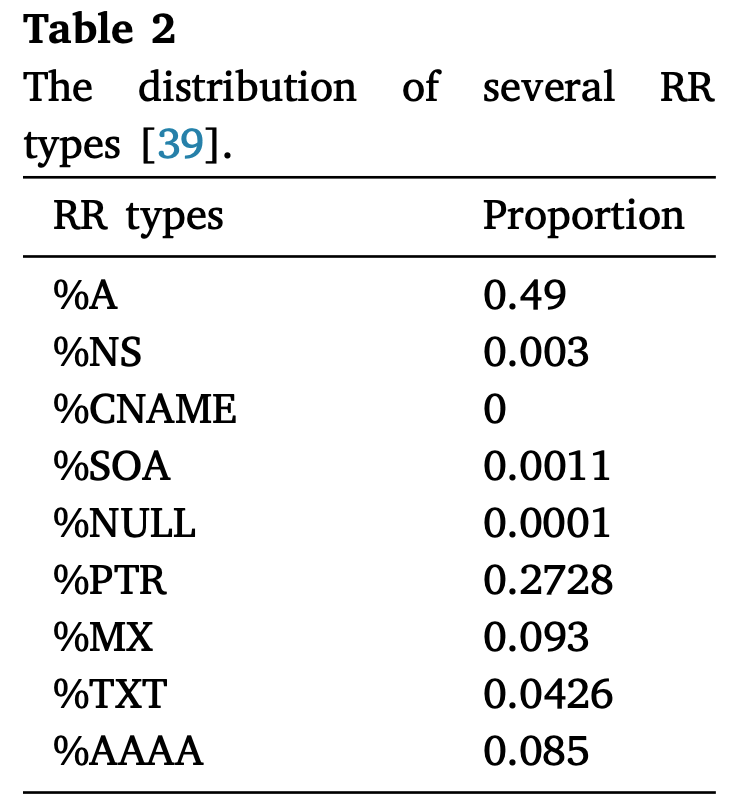
- 하지만 DNS tunneling 에서는 용도에 맞는 type 을 사용하는 것이 아니고, bandwidth 를 극대화시킬 수 있는 type 을 사용하기에, 자주 사용되지 않는 type 을 사용하곤 한다.
- 가령 많은 DNS tunneling tool 들이
TXTtype 을 사용하고, 따라서 이러한 성질을 이용한 detection tool 들이 많이 개발되었다. - 하지만 이것은 다른 type 을 사용하면 되기에 언제든지 회피할 수 있고, TUNs 와 같은 tool 은
CNAME만을 사용하는 등의 예외 케이스들이 있다. - 따라서 의심해봄즉 할만한 dns type 리스트를 만들어놓고 알림을 걸어놓는 방식으로 대비할 수 있다.
(2) Signature of specific DNS tunnel tools
- 일단 중요한 것은 여기서 말하는 Signature 은 TLS Signature 은 아니다; 그것보다는 약간 “DNS tunneling 을 암시하는 특정 문자열” 이라고 생각하면 된다.
- 가령 ‘OpenSSH’ 는 Base64 로 바꾸면
T3BlblNTSA==가 되고, 이러한 문자열은 dns tunneling 의 가능성을 시사하기에 signature 로 볼 수 있는 것.
- 가령 ‘OpenSSH’ 는 Base64 로 바꾸면
- 일부 dns tunneling tool 들은 victim 과 attacker 간의 통신 형식을 맞추기 위해 이러한 특정 문자열을 사용할 때가 있고, 이러한 성질을 이용하는 것이 Signature-based detection 이다.
- 다만 이러한 방법은 Well known signature library 를 구축하는 것에 많은 시간이 소요되고, 알려지지 않았거나 새로운 dns tunneling tool 에 대해서는 감지하지 못한다는 문제가 있다.
- 더 구체적인 사례는 섹션 4.1.1 에서 살펴보자.
(3) Policy violation
- 이것은 Direct connection mode 에서만 적용되는 방법이다.
- 만약 특정 DNS server 와만 통신이 가능하도록 설정된 시스템에서는 이러한 attacker nameserver 와 통신하는 것 자체가 정책 위반이기 때문.
- 물론 아주 특수한 케이스이기에 많이 사용되지 않는다.
3.2. Traffic-based feature
#draft 나중에 정리할 예정입니다.
4. DNS tunnel detection
4.1. The rule-based detection
4.1.1. The signature-based methods
- Signature 를 이용해 DNS tunnel 을 감지하는 사례를 표로 정리해 보면 다음과 같다:
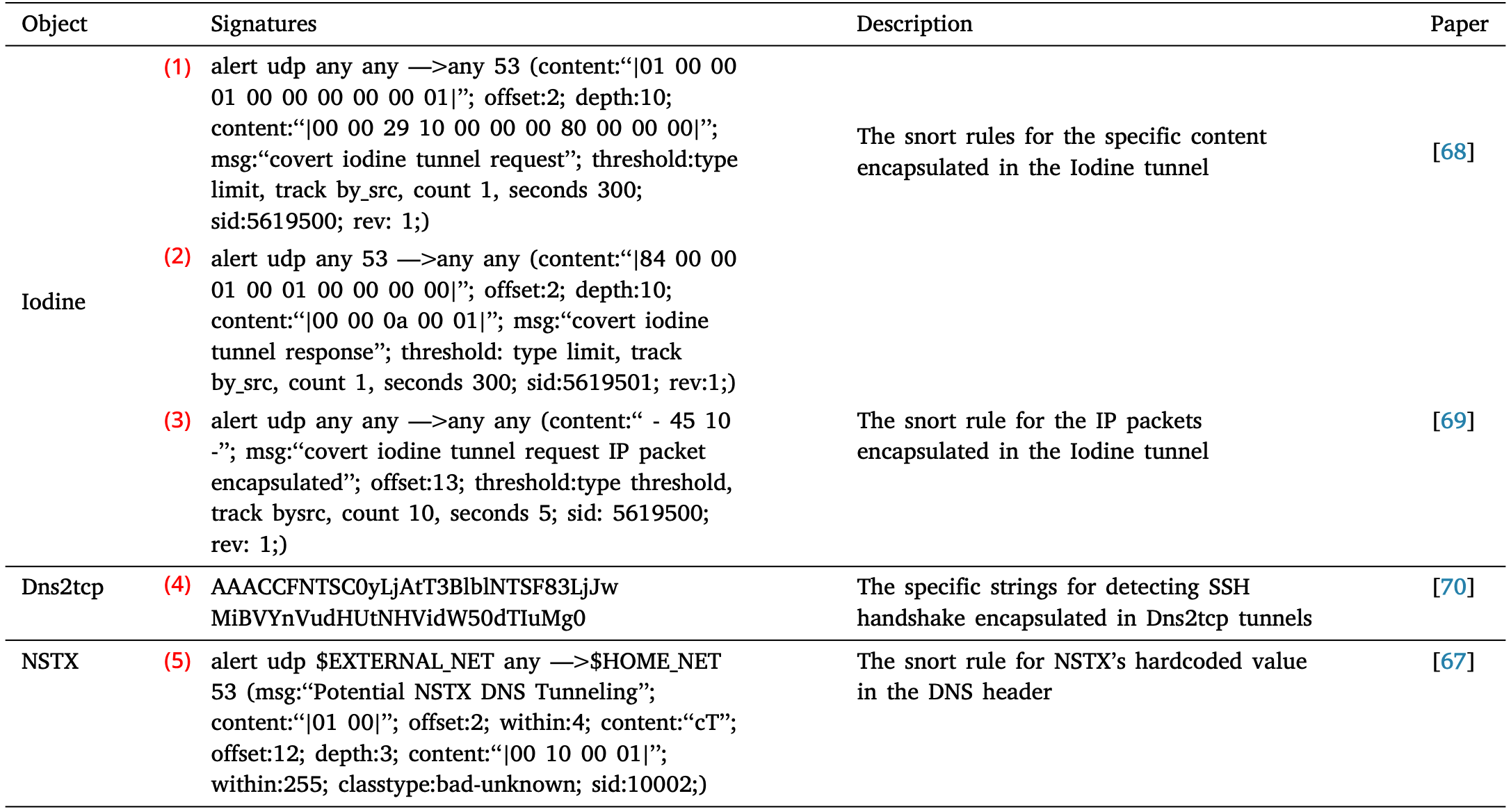
- 1, 2번:
- 1, 2번의 Snort rule 은 Detection of DNS Based Covert Channels 논문에 제시된 것인데, 여기에서도 자기네들이 고안한 것은 아니다.
- 이 방법은 2009년에 Michel Chamberland 란 사람이 자기 블로그에 올린 것인데, 지금은 도메인이 만료되어 더이상 접근이 안된다… (관련 트위터)
- 3번:
- 이 Snort rule 은 Winning tactics with DNS tunnelling 논문에 제시된 것인데, 이것도 자신들이 고안한 방법인지는 잘 모르겠다.
- 원리는 저 offset 13 에 등장하는
45 10이라는 숫자가 중요한데, 저것이 IP packet 을 암시하기 때문이다.- IP packet 에 따르면, IP packet 의 첫 값은 IP version 으로 여기서는 4, 즉 IPv4 를 의미한다.
- 두번째 값인 5 는 Internet Header Length (IHL) 로, 5는 bit 를 의미한다.
- 세번째와 네번째 값인 10 은 binary 로는
0001 0000인데,- 여기에서 6bit (
000 100) 은 Differentiated Service Code Point (DSCP) 를 의미하며,000은 Service class 가 Standard 임을,100은 Drop probability 가Medium이라는 것을 의미한다. - 그리고 나머지 2bit (
00) 은 Explicit Congestion Notification (ECN) 값으로, ECN 을 지원하지 않는다는 의미이다.
- 여기에서 6bit (
- 4번:
- 간단하다.
SSH-2.0-OpenSSH_7.2p2 Ubuntu-4ubuntu2.에 대한 Base64 encoding 이다. - 이 방법은 A Multi-Stage Detection Technique for DNS-Tunneled Botnets 논문에서 처음 제시되었는데, False negative 가 10% 정도로 높게 나왔다고 한다.
- 하지만 이것은 SSH variation 으로 “OpenSSH” 만을 고려했기 때문이고, 다른 SSH tool 도 같이 고려한다면 이러한 false negative 는 낮아질 것으로 저자는 주장하였다.
- 간단하다.
- 5번:
- 이것은 NSTX 라는 이제는 잘 안쓰이는 DNS tunneling tool 에 하드코딩되어 있는 값을 이용하는 방법이라고 한다.
장단점
- 장점은 DNS tunnel 의 킹능성이 높은 문자열을 signature 로 등록해 놓기 때문에, false positive 가 낮다는 점이다.
- 반면에 단점은
- 이런 signature 를 모으는 것은 생각보다 쉽지 않으며
- signature 들을 모았다고 하더라도 dns tunnel 의 입장에서는 그러한 signature 을 사용하지 않으면 그만이기 때문에 회피하기도 아주 쉽다는 것이다.
4.1.2. The threshold-based methods
#draft 나중에 정리할 예정입니다.
4.2. The model-based detection
- Model-based detection 은 ML 이나 DL 모델을 이용해 DNS tunnel packet 들의 특징들로부터 rule 을 자동으로 생성해 내 detection 하는 방법이다.
- 크게 ML 을 이용한 방식, DL 을 이용한 방식 두 가지가 있다고 한다.
- ML 모델은 data processing 과정에서 tunneling domain 의 특징들을 전문가가 직접 추출해 내야 하는 반면 1
- DL 모델은 이런 특징들을 자동으로 추출하고 패킷 구조와 순서 정보도 최대로 활용할 수 있다 2 고 한다.
4.2.1. The traditional machine learning-based methods
- ML 은 경험으로부터 paramter 를 조작해 점진적으로 성능을 개선해 나가는 모델 개발 방법이다.
- Feature engineering 부터 시작한다고 한다 - 어떤 feature 을 detecting 할지를 정하고, 그에 적합한 algorithm 을 정하는 과정
Unsupervised learning
- Isolation Forest
- 별로 사용 안한다. Benign sample 을 학습하는 용도? 로만 사용되었다고 한다.
- Real-Time Detection of DNS Exfiltration and Tunneling from Enterprise Networks
- Research institute, Campus 데이터셋 각각 % 와 % 의 정확도가 나왔다고 한다.
- K-means
- Detection of Exfiltration and Tunneling over DNS
- DNS tunneling detection 은 command transfer 에 초점을 맞춰 % 의 낮은 정확도 (true positive) 를 보여줬다.
- Data leakage 의 경우에는 downdata 에 command 가 들어가기에 encoded subdomain 의 길이가 훨씬 짧다.
- 따라서 짧은 substring 이 더 detection 하기 힘들기에 이런 낮은 정확도가 나오는 것
- 반면, DNS tunneling 의 data leakage 는 DNS tunneling 이 아닌 다른 공격으로 분류했는데, (물론 classification 은 잘못되었지만) % 라는 높은 정확도를 보여줬다.
- Logistic regression alg
- TXT record type 에 대한 통계적인 특성 (encoded data 에 초점)
- DNS tunneling detection 은 command transfer 에 초점을 맞춰 % 의 낮은 정확도 (true positive) 를 보여줬다.
- Detection of DNS Tunneling in Mobile Networks Using Machine Learning
- Open class support vector machine (OCSVN) 이 모바일 환경에서는 K-means 보다 더 성능이 좋다고 한다.
- 추가적으로 논문에서는 K-means 는 cluster 내의 data 개수가 유사할 때 더 좋은 성능을 내지만 DNS tunneling 의 경우에는 malicious packet 의 수가 극히 적기 때문에 K-means 보다는 ocsvn 이 더 성능이 좋았다고
- 근데 이상한건 위에 나온 logistic regression 과 ocsvn 이 모두 supervised model 이라는 것이다.
- Detection of Exfiltration and Tunneling over DNS
Supervised learning
- DNS Tunneling Detection with Supervised Learning
- 에서는 때로는 supervised learning 이 unsupervised learning 보다 더 성능이 좋다고 주장한다.
- CLR: A Classification of DNS Tunnel Based on Logistic Regression 에서는 logistic regression alg 를 사용해서 99% 를 달성했다는데
- Support Vector Machine (SVM)
- Detecting DNS Tunnel through Binary-Classification Based on Behavior Features
- Decision tree, SVM, Logistic regression 세개를 이용해 detection 수행
- offline 에서 학습을 하고 online 에서 추론
- Time interval, Request packet size, Sub-domain entropy, resource record type 4가지 특징 이용
- Window size 가 10일때, SVM 에서 99.77% 라는 정확도를 보여줬다
- Multilabel SVM 이 Multilabel Bayesian alg 보다 좋았다
- kernel SVM 이 linear SVM 보다 좋았다고 한다.
- Detecting DNS Tunnel through Binary-Classification Based on Behavior Features
- Random Forest (RF)
- Detection of Tunnels in PCAP Data by Random Forests
- Complex defence-in-depth enterprise 환경에 대한 RF 방법 제안
- DNS tunnel Trojan detection method based on communication behavior analysis
- Source IP, Source port, L4 protocol, Destination IP, Destination port 5개의 정보에 따라 트래픽을 군집화한 DNS flow session 을 정의했다
- True positive 가 98.47% 였지만 false positive 가 5-7% 였다고 한다
- 이 이유는 Qihoo 360 사의 제품을 사용중에 여기서 DNS tunneling 과 비슷하게 생긴 dns query 를 주기적으로 날렸기 때문이라고 함.
- 따라서 이런 상황에서는 whitelist 로 관리하면 될 것이다.
- 이러한 DNS flow session 을 통해 (UDP 는 TCP 와 달리 이러한 flow control session 이 없기 때문에) session duration 같은 특징들을 추가적으로 추출해낼 수 있었다.
- UDP 에서는 session 이란 것이 없기 때문에 통신 지속 시간 (duration) 을 알 수 없었지만,
- 이런 DNS flow session 을 도입함으로써 이런 특징을 활용할 수 있게 되었고
- DNS tunneling 은 일반적인 DNS query 보다 이런 지속시간이 더 길기 때문에
- Detection 의 새로운 가능성을 열었다고 할 수 있는 것
- Detection of Tunnels in PCAP Data by Random Forests
이후 생략... #draft