참고한 것들
Compensation Log Record: CLR
ABORT를 처리하기 위해서, 아니면 Recovery 를 위해서 UNDO 를 하는 와중에 crash 가 났다고 해보자.- 그럼 UNDO 작업을 다시 해야 될텐데, 이게 너무 비효율적인 것 같다 이거야.
- 왜냐면 UNDO 하다가 crash 나는 것이 반복되면, 하염없이 UNDO 만 하고 있을테니까.
- 그래서 UNDO 작업을 할 때, 이 UNDO 작업에 대해서도 Logging 을 하는 것이 Compensation Log Record (CLR) 이다.
- 이놈은 기본적으로
UPDATElog 와 동일한데, 여기에 UndoNext 가 추가되어 이것 다음에는 어떤 log 를 UNDO 해야 하는지 LSN 으로 표시해 놓는다.- 이것 덕분에 만약에 UNDO 하다가 crash 가 나더라도, 해당 UNDO 를 다시 할 필요 없이 여기 나와있는 UndoNext 를 보고 바로 crash 전에 하던 UNDO 작업으로 뛰어가 계속 UNDO 를 이어갈 수 있다.
- 결과적으로 계속 crash 가 나도 recovery 시간은 점점 짧아진다.
- 이것을 그림으로 그려보면 다음과 같다.
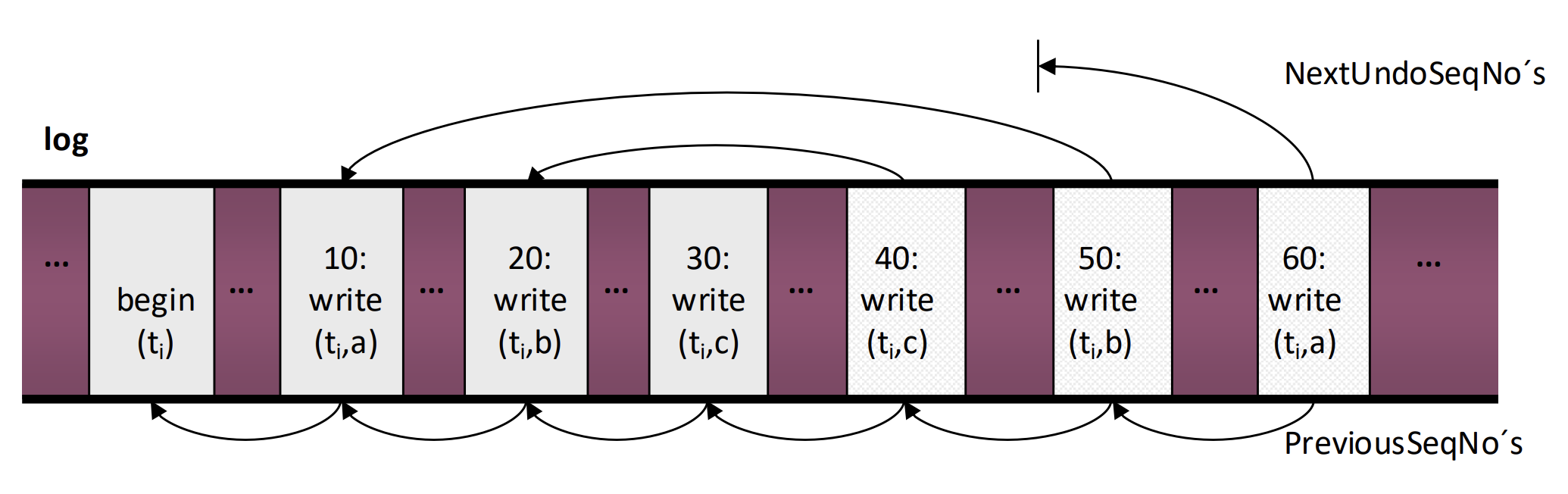
- 이 그림은 UNDO 도중 crash 가 나지 않고 recovery 가 종료되었다고 가정했을 때의 log 형상이다:
- 10 ~ 30 까지는 normal operation log 이고, 30 ~ 40 사이에서 crash (혹은
ABORT) 가 나서, 40 ~ 60 는 UNDO 과정에서 생긴 CLR 이라고 생각하면 된다.
- 10 ~ 30 까지는 normal operation log 이고, 30 ~ 40 사이에서 crash (혹은
- 우선 30 ~ 40 구간에서 crash 가 나서 recovery 를 하는 것을 생각해보자.
- 이때는 30 까지는 정상적으로 REDO 를 할 것이고, 그 다음 UNDO 를 하며 CLR 을 생성하기 시작할 것이다.
- 40 까지 CLR 을 생성한 다음 두번째 crash 가 발생했다고 해보자.
- 그럼 두번째 recovery 에서는 40 까지 REDO 를 할 것이고, 따라서 이 REDO 를 따라가는 것만으로도 20 ~ 30 구간에 대해서는 UNDO 가 완료된다.
- 그럼 40 까지 REDO 를 하며 온 다음 UNDO 를 시작할 때는 40 이 UndoNext 로 가리키고 있던 20 으로 날아가 UNDO 를 하게 된다.
- 그렇게 해서 10까지 UNDO 를 해 50 까지 CLR 을 생성한 이후에 세번째 crash 가 발생했다고 해보자.
- 그럼 마찬가지로 세번째 recovery 에서는 50 까지 REDO 를 할 것이고, REDO 가 완료되면 자연스럽게 10 까지 UNDO 가 완료되게 된다.
- 이후 세번째 UNDO 에서는 CLR 50 의 UndoNext 인 10으로 날아가서 UNDO 를 시작하게 되고, 정상적으로 종료된다.
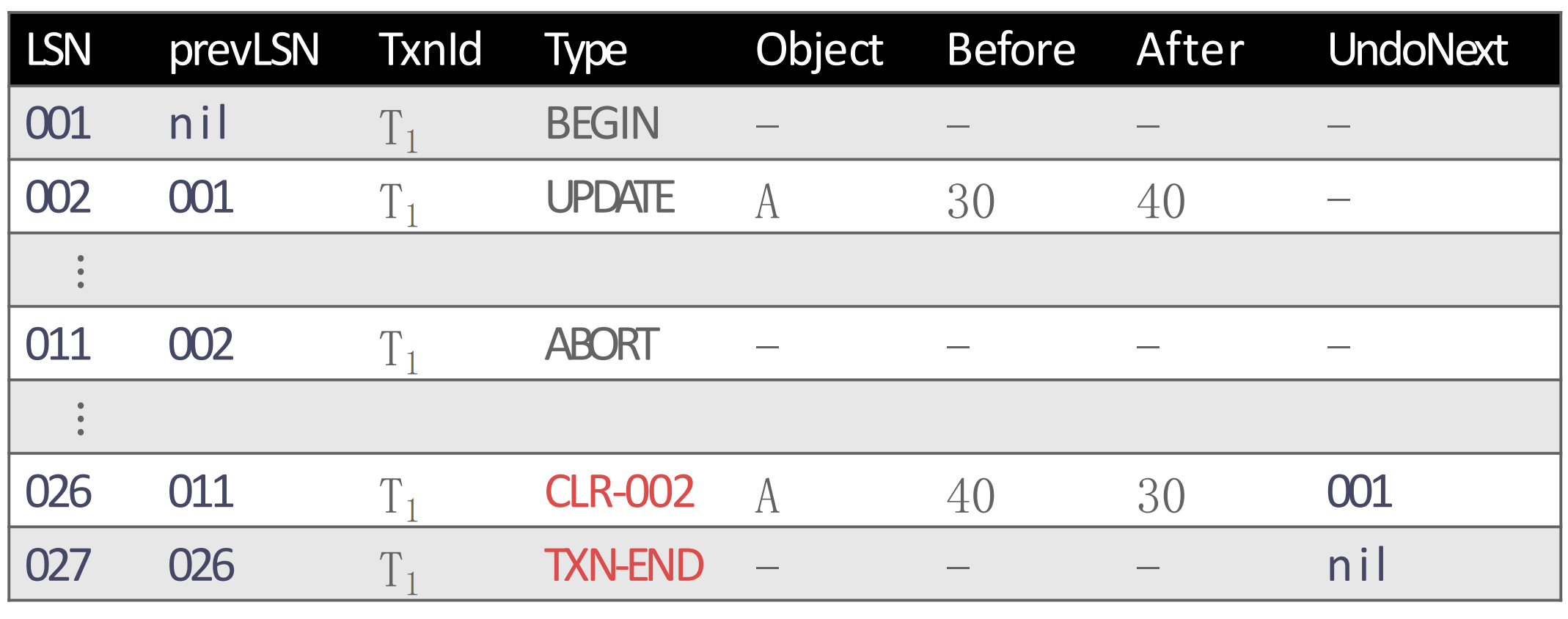
CLR Example
- CLR 이 어떻게 생겼냐 예시로 살펴보자.
- 우선 다음과 같이 011 에서
ABORT가 났다.
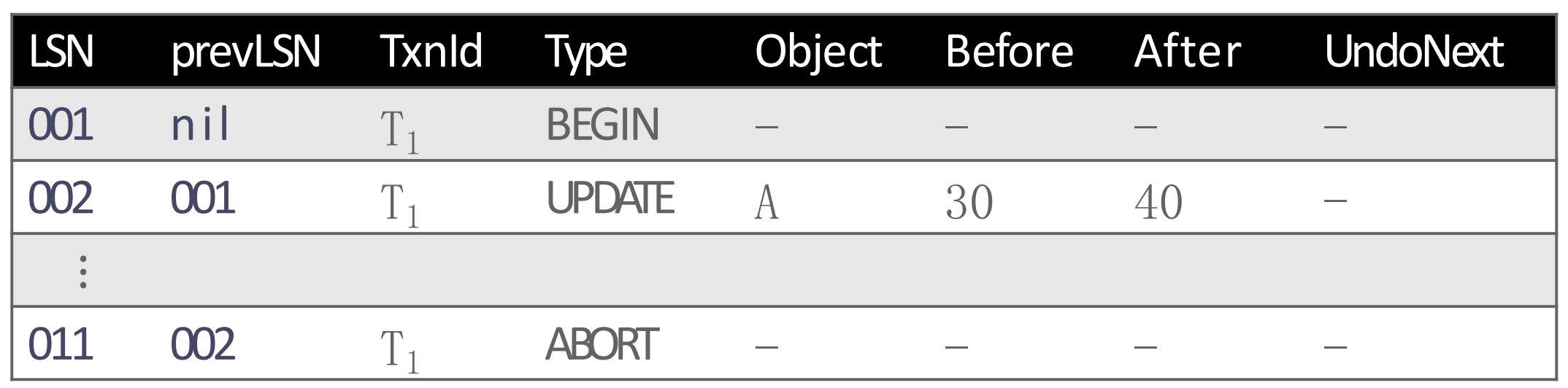
- 그럼
ABORT이기 때문에 해당 txn 에 대해서만 UNDO 를 해야 한다. 처음으로 UNDO 해야 할 log 는 002 이기 때문에, UNDO 를 하고 CLR-002 를 생성한다.
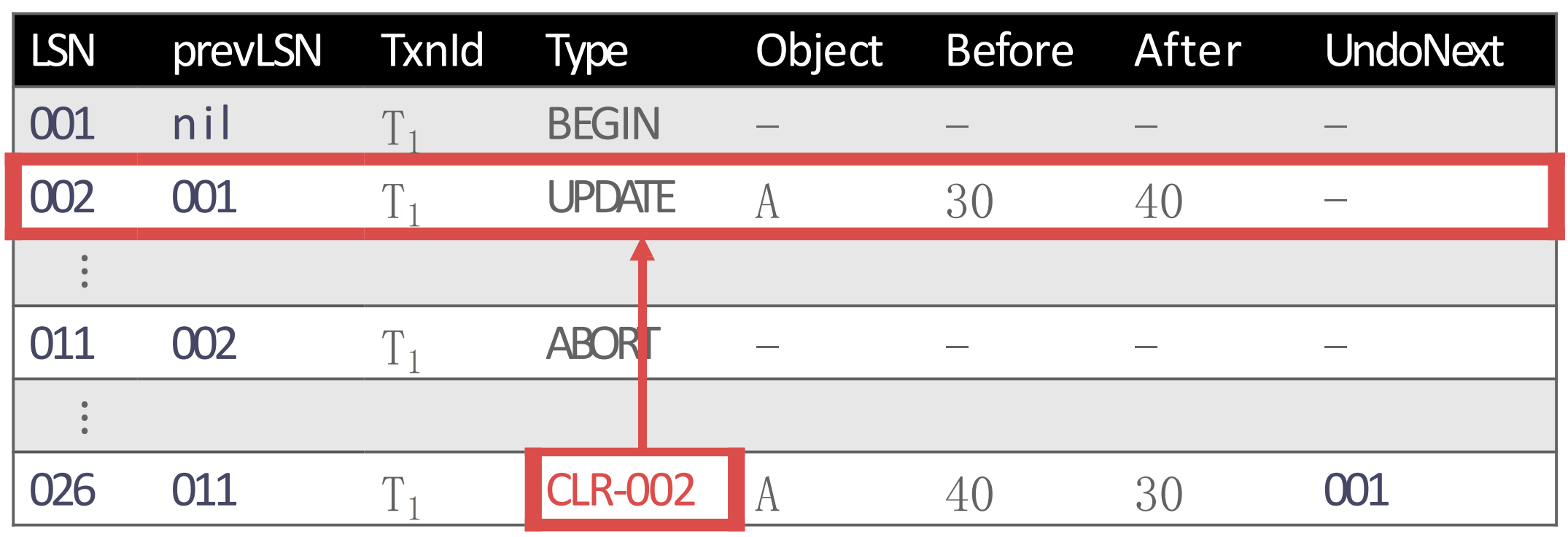
- CLR 은 기본적으로 UPDATE log 인데, UNDO 라고 했다. 따라서 여기에는 원래의 UPDATE log 에서 before 와 after 가 반대로 들어간다.
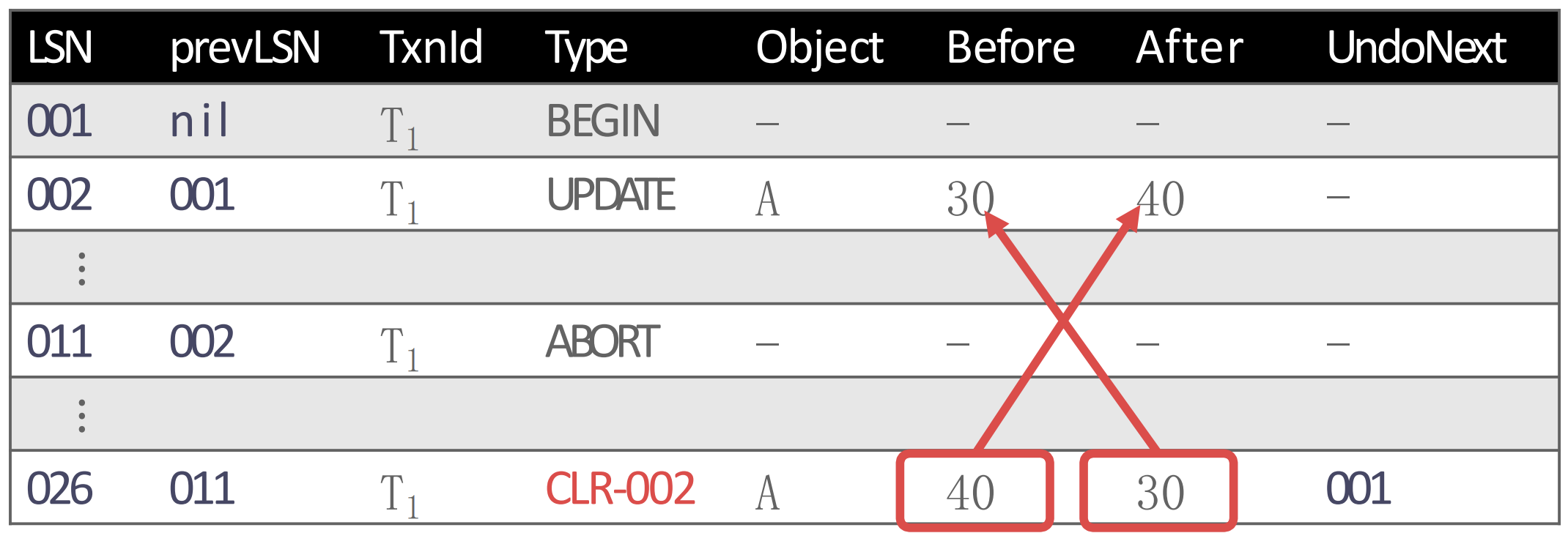
- 또한 002 의 PrevLSN 이 001 이기 때문에, 다음으로 UNDO 할 것은 001 이다. 따라서 CLR 의 UndoNext 에는 001 를 적어준다.

- 그리고
ABORT에 의한 UNDO 이므로 이것을 완료한 다음에는TXN-END를 넣어준다.