원본 논문
- 이 글은 Scalable Database Logging for Multicores, VLDB’18 논문을 읽고 정리한 글입니다.
- 별도의 명시가 없으면, 본 논문에서 그림을 가져왔습니다.
#draft 본 문서는 부분적으로 완료된 상태입니다.
4.2. Tracking LSN Holes
4.2.2. SBL-crawling Algorithm
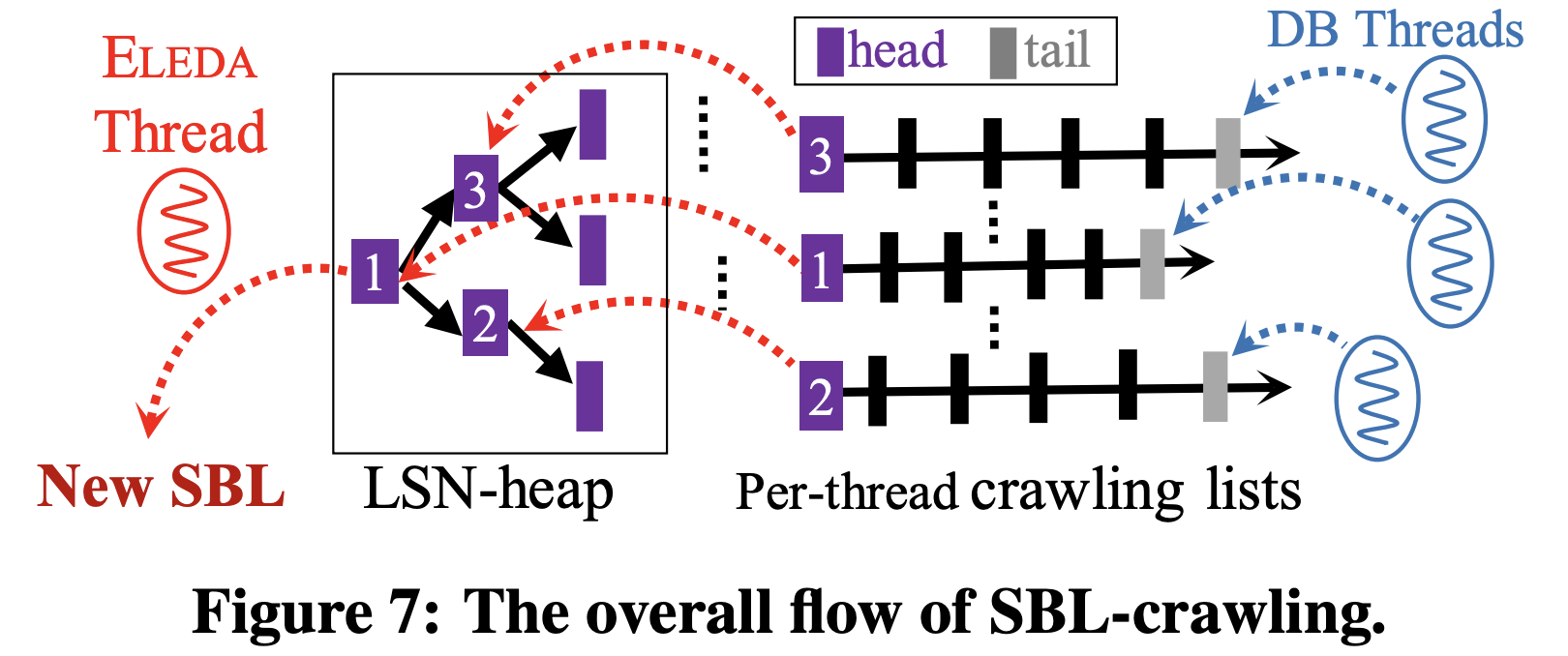
- ELEDA 에서는 SBL 을 위와 같은 모습으로 찾아나간다.
- 우선 가장 핵심 아이디어는 다음과 같다.
- 각 DB thread 마다 crawling list 를 갖고 있고, thread 는 log copy 가 완료된 LSN 을 이 list 에 넣는다.
- 그리고 이 list 들의 head 들을 이용해 LSN-heap 을 빌드해 copy 가 완료된 가장 작은 LSN 을 뽑아낸 후, 이것이 SBL 와 연속적이라면, 그것을 SBL 에 추가하는 형태이다.
- 좀 더 구체적으로 말하면, log 의 시작 LSN (start_lsn) 이 SBL 와 같으면 이 말은 이 log 의 LSN space 가 SBL space 와 연속적이라는 말이기 때문에 log 의 끝 LSN (end_lsn) 이 SBL 로 설정되는 방식으로 SBL 이 advance 된다.
- 따라서 LSN-heap 의 leaf 의 수는 DB thread 들의 개수와 같게 된다.
- 그럼 이때 이러한 자료구조에서 concurrency 는 다음과 같이 보장된다.
- 우선 각 DB thread 들이 건들 수 있는 field 는 list 의 tail 이 전부이다.
- 그리고 ELEDA worker thread 는 이 list 의 head 를 건드려 head 가 가리키고 있는 LSN 들을 LSN-heap 에 넣기 때문에, 이 모든 thread 들 간에 data race 는 발생하지 않는다.
- 즉, DB thread 들이 producer 가 되고 ELEDA worker thread 는 consumer 가 되는 것.
- 근데 이때는 문제가 있다.
- 위 방식이 producer-consumer 인데, producer 는 너무 많고 consumer 는 너무 적다는 것.
- 이에 따라 너무 SBL 이 뒤쳐지게 되면 SBL-hopping 방식으로 전환한다고 한다.
#draft 이후
c_list와h_list관련 내용이 더 있는데 나중에 정리.